1. 병렬 프로그래밍의 필요성
1.1. 무어의 법칙 (Moore’s Law)
무어의 법칙 (Moore's Law)
집적회로(IC, Integrated Circuit)에 들어가는 트랜지스터의 개수가 2년마다 2배로 늘어난다
- 컴퓨터의 연산 성능만 증가하면 자연스럽게 기존 프로그램도 빨라짐 (Free Lunch Era)
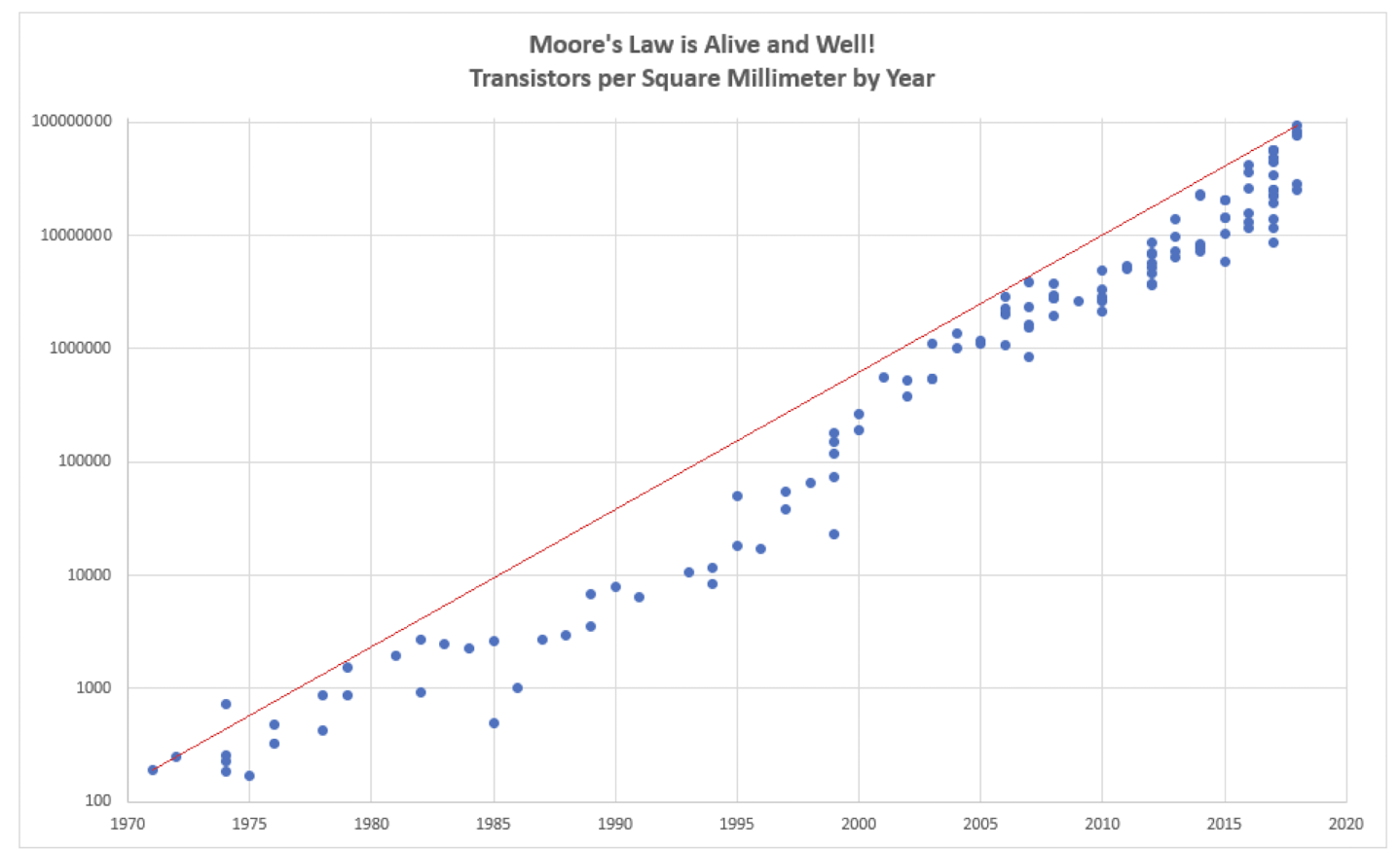
이에 대한 근거로 무어는 다음과 같은 5가지 근거를 들었다.
- 저가격화: 회로 소자를 만드는 데 드는 가격이 점점 낮아지고 있다.
- 소형화: 트랜지스터의 크기가 점점 작아지고 있으며 범용 환경에서 사용될 수 있도록 편의성이 증가하고 있다.
- 고성능화: 전자적 회로 길이가 짧아지고 있기 때문에 동작 속도가 증가하고 있다.
- 저전력화: 실장 되는 트랜지스터의 개수는 증가하고 있지만 소모 전력은 감소하고 있다.
- 단일 웨이퍼 위에 트랜지스터가 선 없이 실장 되어 연결되기 때문에 서로 간섭해서 오류를 발생시킬 확률이 감소하고 있다.
이러한 무어의 법칙은 50년 넘게 정설처럼 여겨졌다
1.2. Dennard Scaling
Dennard Scaling
트랜지스터 크기를 줄이면 전력과 전압도 비례해서 줄어든다
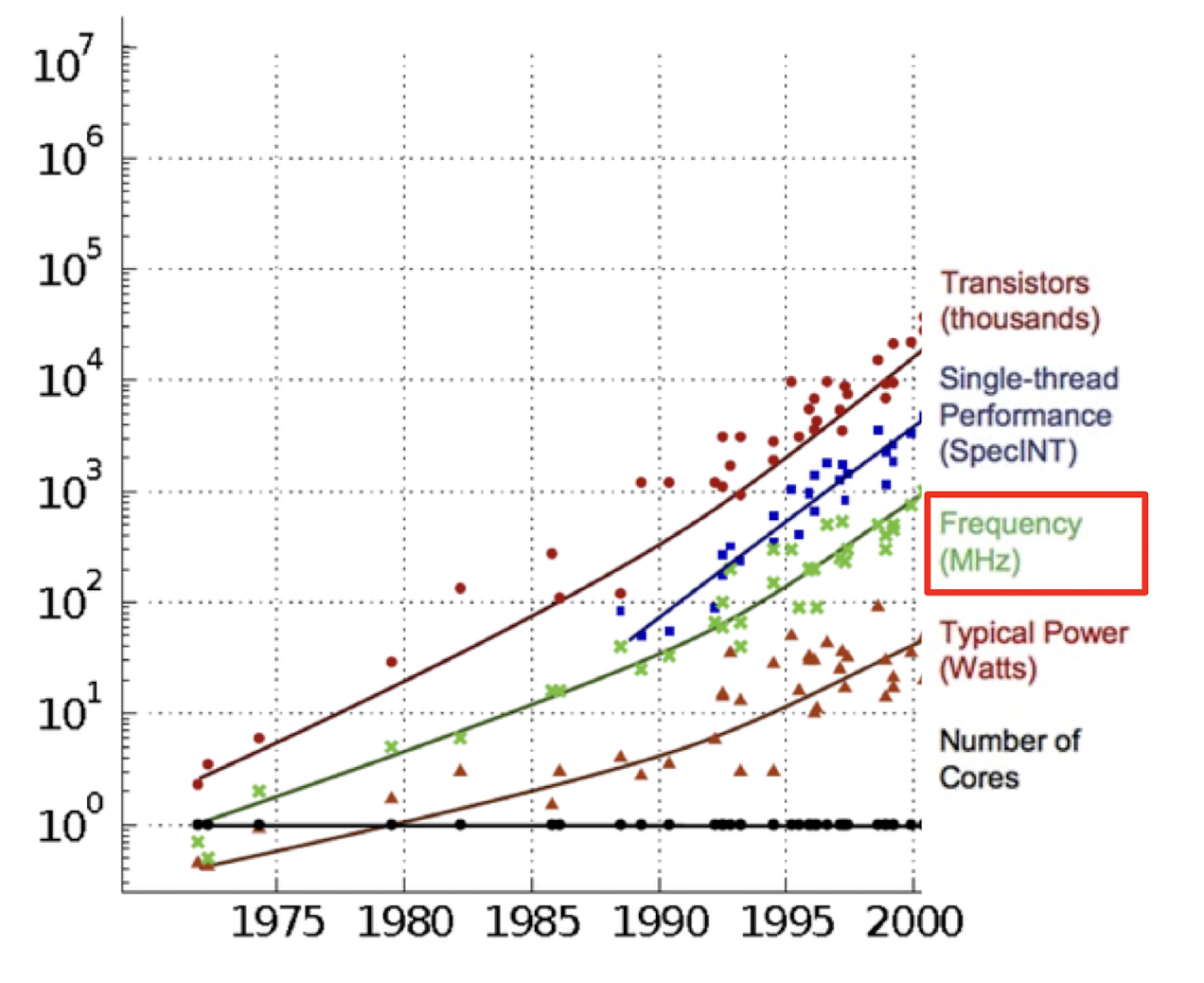
트랜지스터 크기를 만큼 줄였을 때 아래 표와 같은 변화가 일어난다.
| 항목 | 스케일링 |
|---|---|
| 트랜지스터 크기 | |
| 전압 | |
| 정전용량 | |
| 클럭 | |
| 소비 전력 | |
| 면적 | |
| 단위면적 전력 밀도 | → constant |
이는 무어의 법칙에 의해 2년마다 트랜지스터의 수는 2배씩 증가하고, 트랜지스터가 소형화되어 IC 회로 집적도가 증가하면서도 소비전력은 유지되는 이상적인 모습을 보이는 듯 했다.
1.3. 무어의 법칙과 Dennard Scaling의 한계
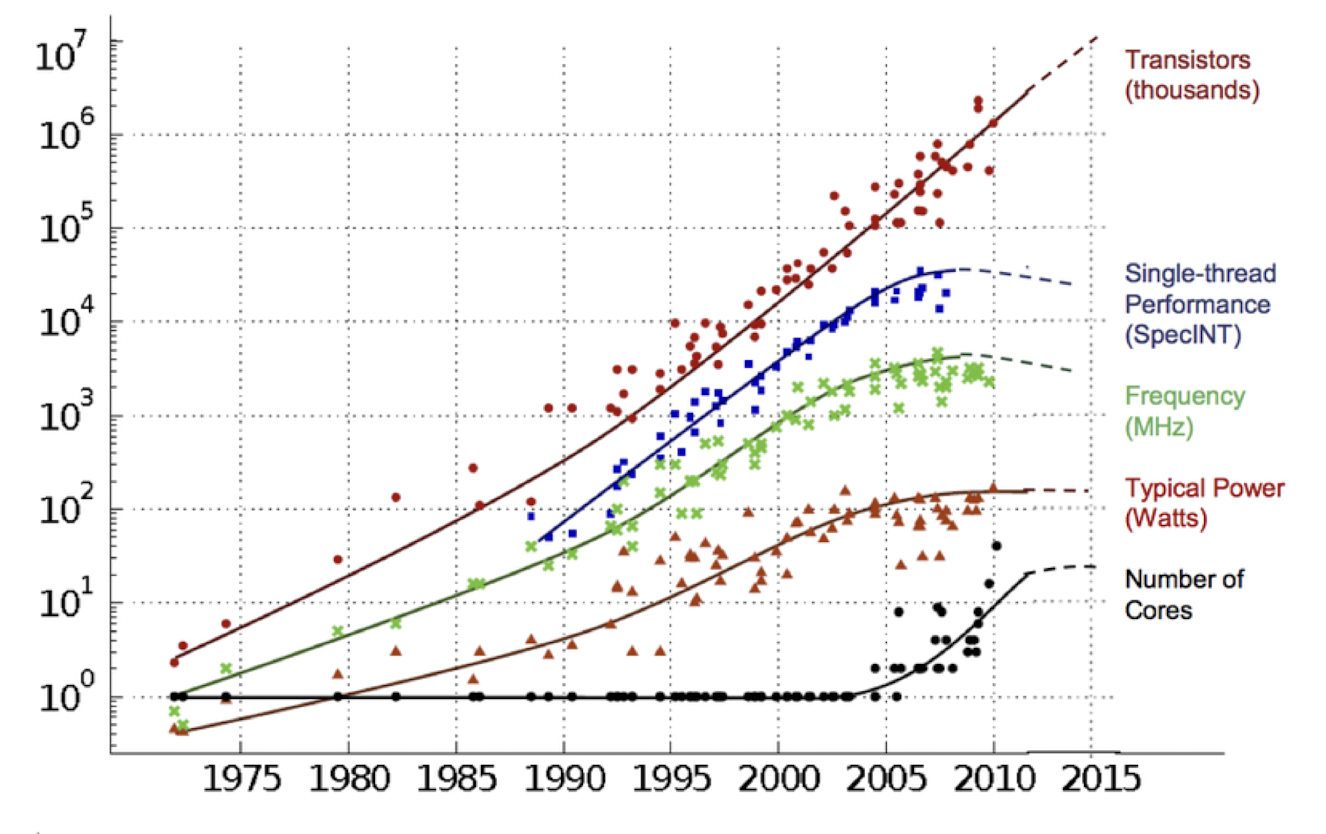
하지만 이러한 이상적인 예측은 한계를 맞이했다. 위의 그래프를 보면 무어의 법칙에 따라 회로 집적도는 증가하지만 클럭 주파수와 소비전력은 더이상 성장하지 못하고 있는 것을 볼 수 있다.
이는 더이상 동작 전압을 낮출 수 없어 발생하는 문제였는데, 다음과 같은 원인들이 있다.
- Threshold Voltage의 한계 (문턱 전압, ) 문턱 전압 는 MOSFET이 “켜지기” 위해 필요한 최소 전압인데, 이를 무작정 낮추면 트랜지스터가 제대로 꺼지지 않아 전류가 흐르는 상태가 되어 회로가 동작하지 않거나 오류 발생률이 증가한다.
- Leakage Current (누설 전류) 증가 트랜지스터가 작아질수록 게이트 산화막이 얇아지고, 터널링 전류(leakage current) 즉, 누설 전류가 발생하여 총 소비전력이 증가한다.
- Signal-to-Noise Ratio (신호 대 잡음비) 감소 전압이 낮아지며 상대적으로 신호 대비 노이즈의 비율이 커졌고, 이로 인한 데이터 오류를 보정하기위한 회로가 추가되며 성능 손해를 야기한다.
동작 전압을 줄이지 못하면 전력 소비는 선형이 아니라 제곱으로 늘어나고 () 더 많은 트랜지스터에서 발생하는 더 많은 누설 전류까지 더해져 전력 밀도가 폭증하게 된다.
이러한 전력 밀도와 누설 전류는 발열 문제로 이어져 클럭 상승이 멈추게 되었다.
이를 Power Wall 이라 한다.
1.4. Power Wall의 해결책
- 병렬화: 낮은 전압, 낮은 주파수의 코어를 여러 개 배치 (멀티코어, GPU, NPU 등)
- 전력 효율 중심 설계: DVFS, 전력 gating, 클럭 gating, 빅리틀 구조, 등
- 전용 하드웨어: 도메인 특화 아키텍처 (DSA, TPU, AI 칩 등)
1.5. Sum Reduction 예제
1.5.1. Naive Sum
int global_sum = 0;
for (int i = 0; i < P; i++) {
global_sum += partial_sum[i];
}- 시간복잡도:
- 통신 병목: 모든 쓰레드가 마스터에게 결과를 전달
- 메모리 병목: sum[0], sum[1], …에 접근하면서 cache line 충돌
1.5.2. Hierarchical Tree Reduction
Step 0: P0 P1 P2 P3 P4 P5 P6 P7 (partial sum)
Step 1: P0 P2 P4 P6 (P0+=P1, P2+=P3, ...)
Step 2: P0 P4 (P0+=P2, P4+=P6)
Step 3: P0 (P0+=P4) ← 최종 결과- 시간복잡도:
- 각 단계에서 절반의 쓰레드만 활동 → 병렬성이 유지되면서도 빠른 수렴
- 통신 경로가 균등하게 분산 → 메모리/네트워크 병목 완화
- 메모리 관점에서의 이점
- 캐시 친화성 향상 인접한 쓰레드끼리 메모리 접근 시 같은 캐시 라인 공유 → Spatial locality
- False Sharing 감소 나이브 방식은 여러 쓰레드가 동일한 global_sum을 갱신하려 할 수 있음 계층적 방식은 서로 다른 지역 메모리를 통해 덧셈 수행 → 캐시 일관성 병목 감소
이런 계층적 방식은 shared memory에서 동작하여 빠르고, 스레드 간 협업이 log₂N 단계만에 끝난다
CUDA에서도 warp reduction, block reduction, grid reduction까지 계층적으로 설계한다
2. 병렬 프로그래밍의 기본
2.1. ILP (Instruction-Level Parallelism)
- ILP 프로그램은 순차적으로 작성되지만, 독립적인 명령어는 내부적으로 병렬로 실행 가능하다!
- Superscalar Processor CPU 내에 파이프라인을 여러 개 두어 명령어를 동시에 실행하는 기술로, 프로세서가 명령어 간의 독립성을 자동으로 찾아내어 병렬로 실행한다. SISD의 일종이다
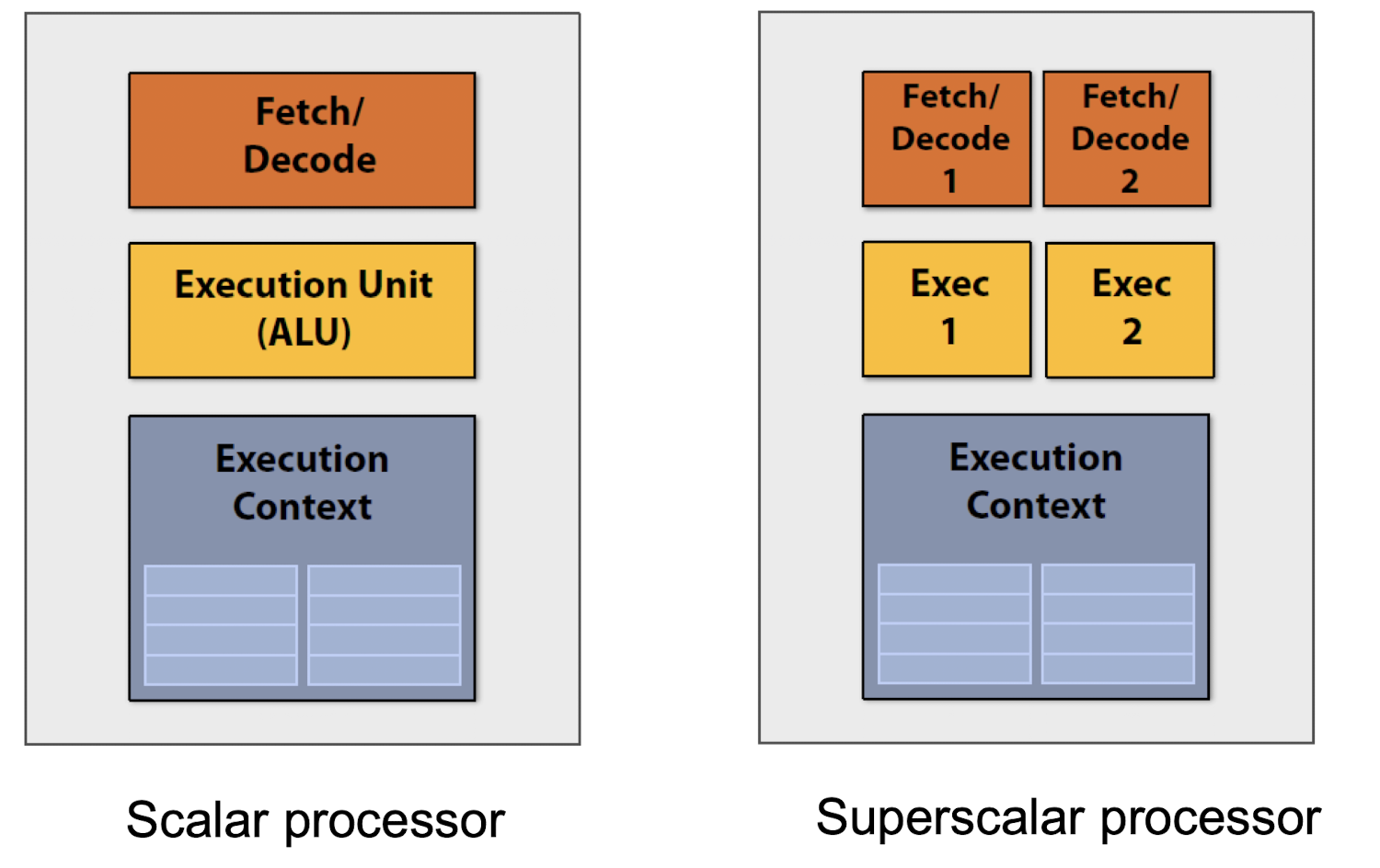
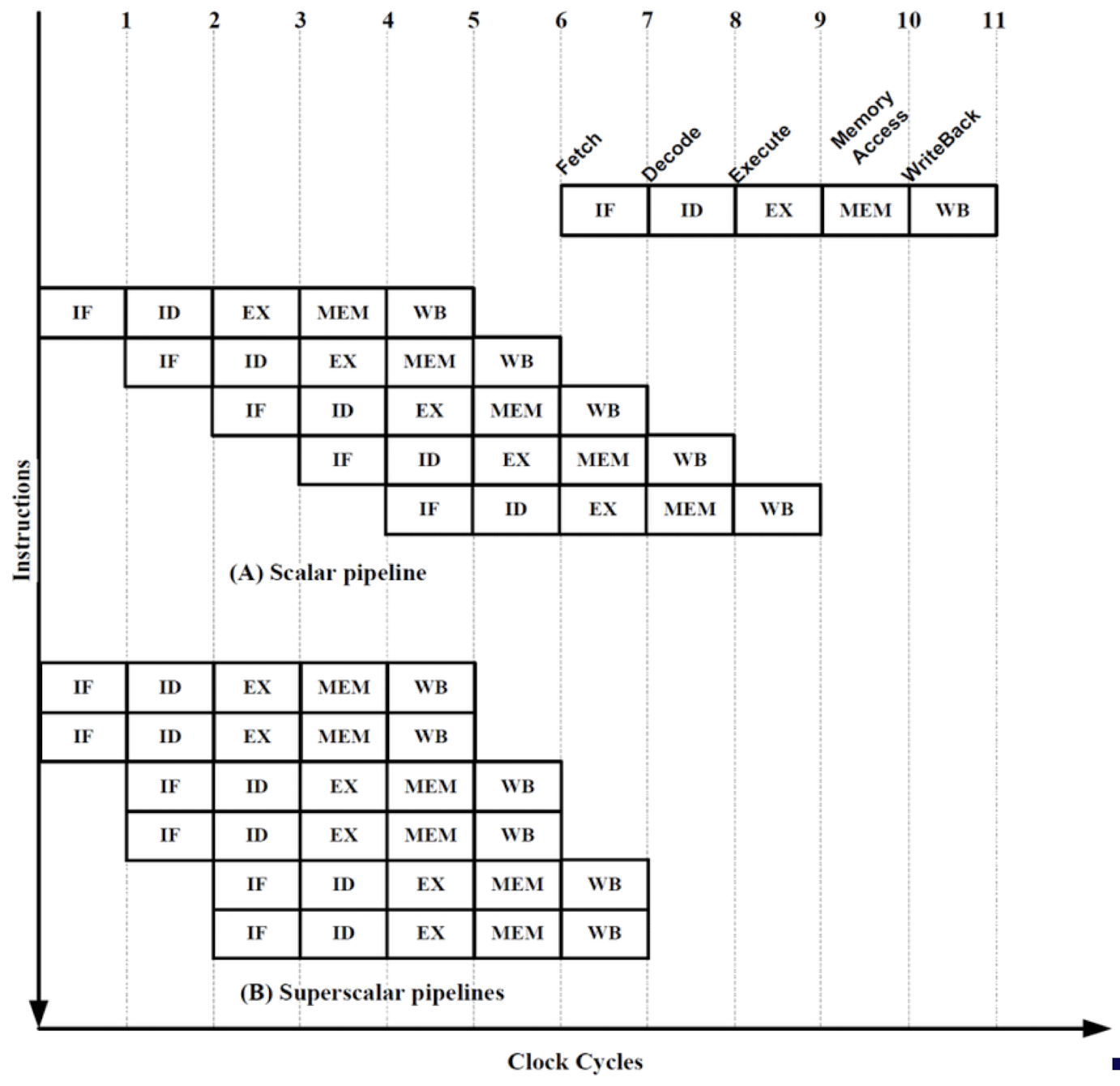
슈퍼스칼라 기법은 여러 의존성에 의해 제약을 가진다.
- 데이터 의존성 (Data Dependency) 첫번째 명령어에 의해 값이 정해지는 데이터를 두번째 명령어에서 읽게 되는 경우에는 두 명령어를 실행 순서가 변경되면 안된다.
add $r3, $r2, $r1
add $r5, $r4, $r3- 자원 의존성 (Structural Dependency) 같은 연산 장치 등 같은 자원을 사용하는 명령어의 경우 해당 연산 유닛의 수가 부족하면 동시에 실행될 수 없다
div $r1, $r2, $r3
div $r4, $r5, $r6
## div 유닛이 하나라면, 두 명령어는 동시에 실행되지 않는다- 제어 의존성 (Control Dependency) 분기(branch) 명령어의 실행 결과가 확정되지 않은 상태에서 다음에 어떤 명령어를 가져올지(Fetch 할지)를 알 수 없다
BEQ R1, R2, target
ADD R3, R4, R5
SUB R6, R7, R8이러한 제약에도 불구하고 하나의 파이프라인에서 동시에 두가지 명령어를 실행하는 슈퍼스칼라 기법은 현대의 대부분 CPU에 탑재되어있다.
2.2. SuperScalar 예제
a = x*x + y*y + z*z위 코드에서 명령어 간 의존성을 정리하면 다음과 같다.
| 단계 | 연산 | 의존성 |
|---|---|---|
| 1 | mul r0, r0, r0 | x |
| 2 | mul r1, r1, r1 | y |
| 3 | mul r2, r2, r2 | z |
| 4 | add r0, r0, r1 | x² + y² |
| 5 | add r3, r0, r2 | 최종 결과 |
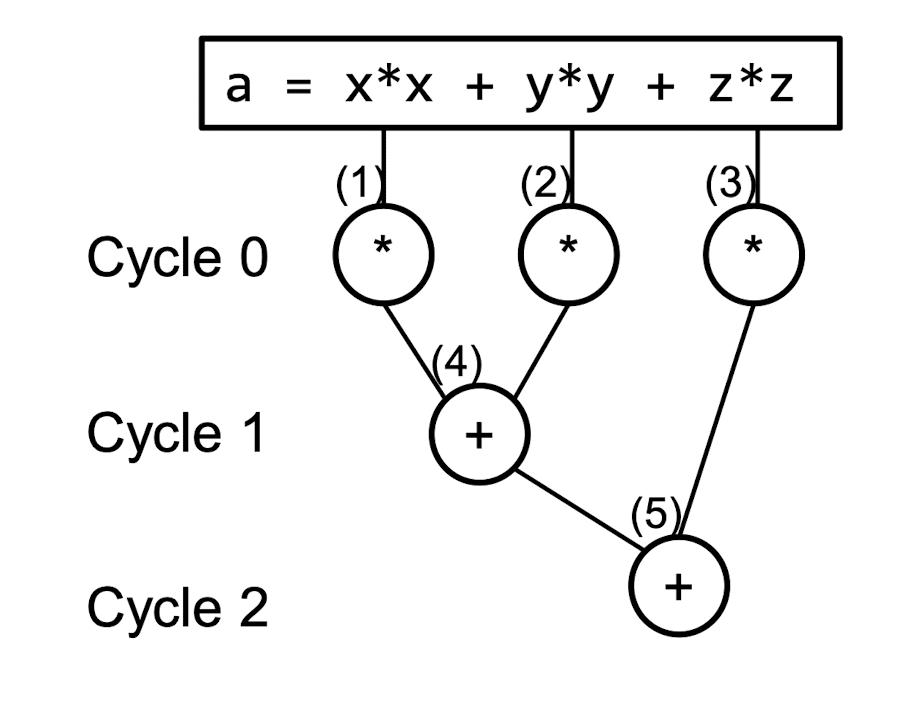
- 순차 실행 시: 5 사이클
- Superscalar: 3개 유닛 → 3 사이클
- 성능 향상 = 하드웨어가 알아서 해줌 → 프로그래머 관여하지 않는다!
2.3. SuperScalar의 한계
| 구분 | 한계 설명 | 원인 |
|---|---|---|
| ① ILP의 한계 | 실제 프로그램 내에서 동시에 실행 가능한 명령어 수가 적음 | 명령어 간 의존성 |
| ② 의존성 문제 | RAW, WAR, WAW 등 데이터 의존성 때문에 병렬 실행 제한 | 데이터 흐름 상 순서 고정 필요 |
| ③ 제어 흐름 문제 | 분기(branch)가 많으면 다음 명령어 예측 어려움 → Control Hazard | 분기 예측 실패 시 flush 발생 |
| ④ 자원 충돌 | ALU, FPU 등 하드웨어 유닛이 부족하면 명령어 병렬 실행 불가 | Structural Hazard 발생 |
| ⑤ 디코더 수 제한 | 한 사이클에 처리 가능한 명령어 수에 제한이 있음 (보통 2~4 issue) | instruction window size 한계 |
| ⑥ 하드웨어 복잡성 증가 | 의존성 추적, 리네이밍, 스케줄링 로직이 복잡 → 소비 전력, 면적 증가 | 성능 대비 효율 저하 |
2.4. Multicore Processor
멀티코어 구조는 클럭 속도는 낮지만 여러 코어를 통해 총 연산량을 증가시킨다.
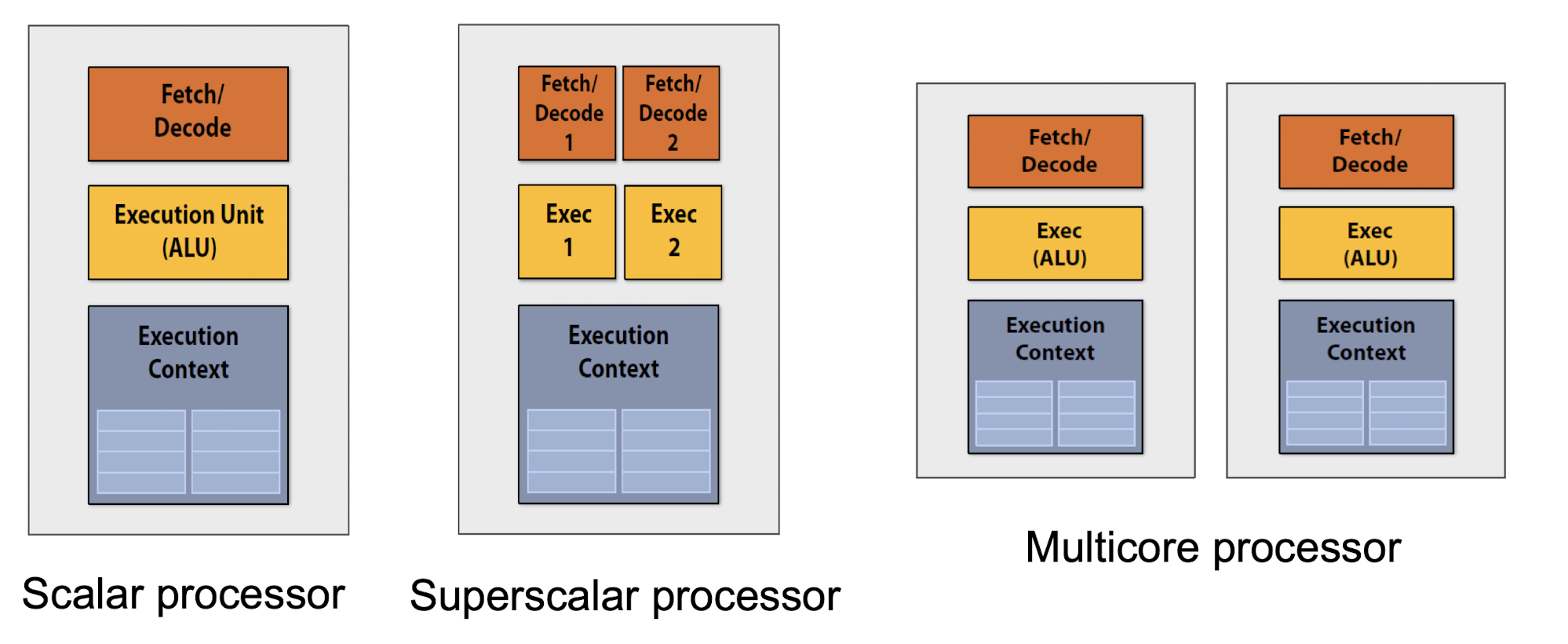 그러면 슈퍼스칼라 프로세서를 못쓰느냐? 하면 그건 아니다. 현대의 대부분 CPU는 슈퍼스칼라 + 멀티코어 프로세서 구조를 모두 갖추고 있다.
그러면 슈퍼스칼라 프로세서를 못쓰느냐? 하면 그건 아니다. 현대의 대부분 CPU는 슈퍼스칼라 + 멀티코어 프로세서 구조를 모두 갖추고 있다.
기본적으로 각 코어에서 서로 다른 프로그램을 실행하는 OS 수준에서의 멀티-프로세스 즉, 프로세스 단위 병렬 처리가 가능하다.
2.5. TLP (Thread-Level Parallelism)
멀티코어 프로세서는 프로세스 단위 병렬 처리에서 나아가 하나의 프로그램을 분산하여 여러 코어에서 실행하는 TLP를 지원한다
다만, ILP인 슈퍼스칼라와 달리 TLP를 이용하려면 프로그래머가 직접 코드를 작성해야 한다
| 구조 | 병렬성 단위 | 병렬화 주체 | 예시 |
|---|---|---|---|
| Superscalar | Instruction-Level Parallelism (ILP) | 하드웨어 (CPU 내부) | 하나의 프로그램 안에서 여러 명령어 병렬 실행 |
| Multicore | Thread-Level Parallelism (TLP) | 프로그래머 or 컴파일러 | 여러 쓰레드, 또는 프로그램을 병렬 실행 |
각 코어는 자기만의 프로그램 카운터(PC)를 가지고 독립적으로 작동하며, 보통은 각 코어가 하나의 쓰레드를 실행한다. (하이퍼스레딩 존재)
멀티코어 프로세서에서 사용하는 TLP의 Thread는 다수의 명령어로 이루어진 프로그램을 여러개의 흐름으로 이를 여러 코어에 명시적으로 분배하여 병렬 처리를 달성한다.
Core 0: 실행 중인 Thread A
Core 1: 실행 중인 Thread B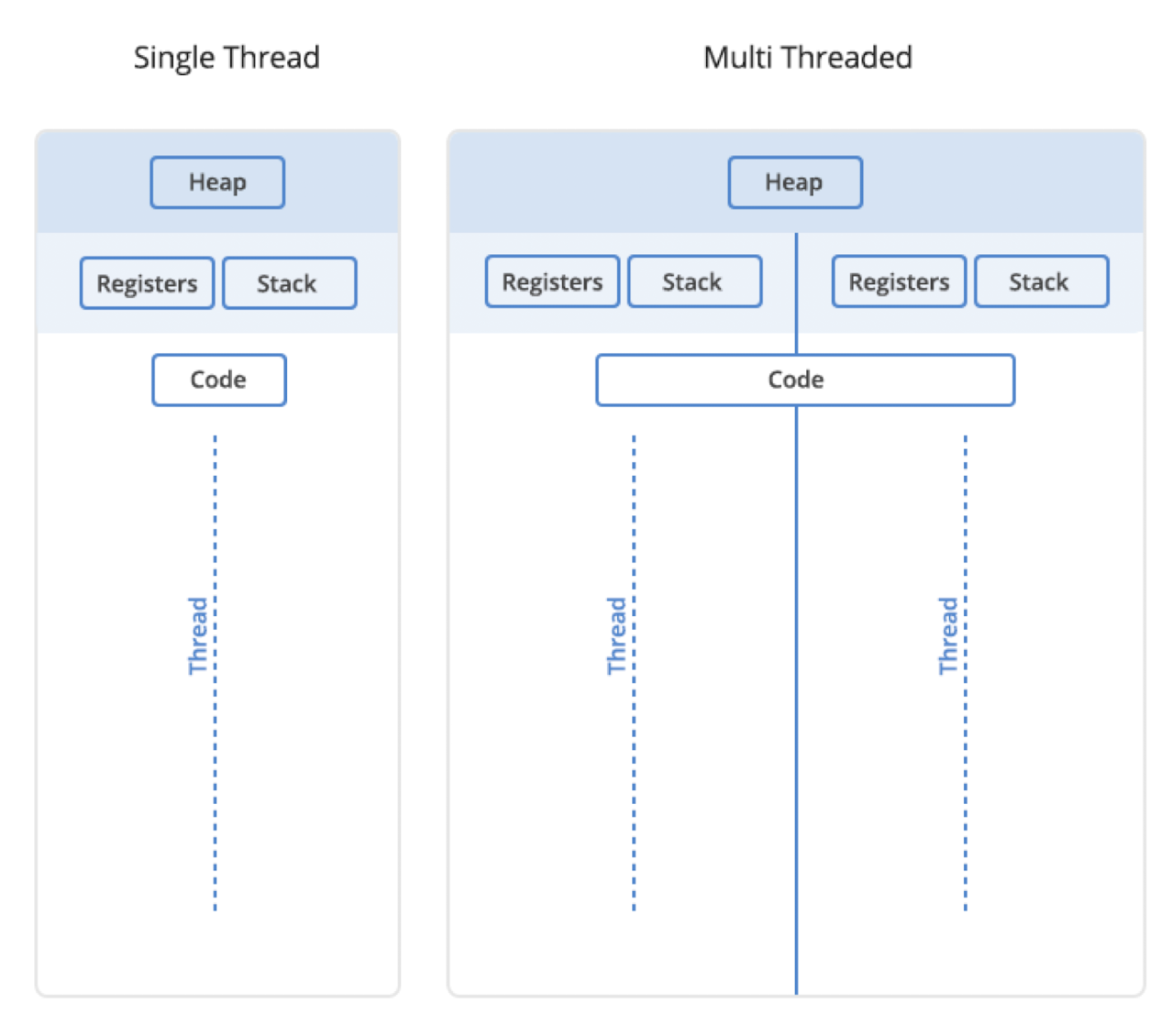
| 개념 | 설명 |
|---|---|
| Process | 실행 중인 프로그램 (코드 + 데이터 + 주소 공간) |
| Thread | 프로세스 내에서 실행되는 작업 단위 (경량 프로세스) |
| 공유 자원 | 코드, 힙 |
| 독립 자원 | 스택, 레지스터 |
2.6. Multi-Thread 예제
2.6.1. 명시적 프로그래밍
void mac(int tid, int num_threads) {
for (int i = 0; i < N/num_threads; i++) {
int idx = tid * (N/num_threads) + i;
c[idx] = k[idx] * a[idx];
c[idx] += k[idx] * b[idx];
}
}- thread마다 독립적으로 작업 영역이 배정
- 작업영역이 겹치지 않으면 race condition 필요 없음
- 동적 분할이 필요하면 OpenMP 등을 써야 함
2.6.2. OpenMP 사용
#pragma omp parallel for
for (long long int i = 0; i < N; i++) {
c[i] = k[i]*a[i];
c[i] += k[i]*b[i];
}#pragma omp parallel for는 자동으로 쓰레드를 나누어 병렬 실행- 루프 독립성 필요
- N=10억 수준의 대규모 연산에서도 손쉽게 병렬화 가능
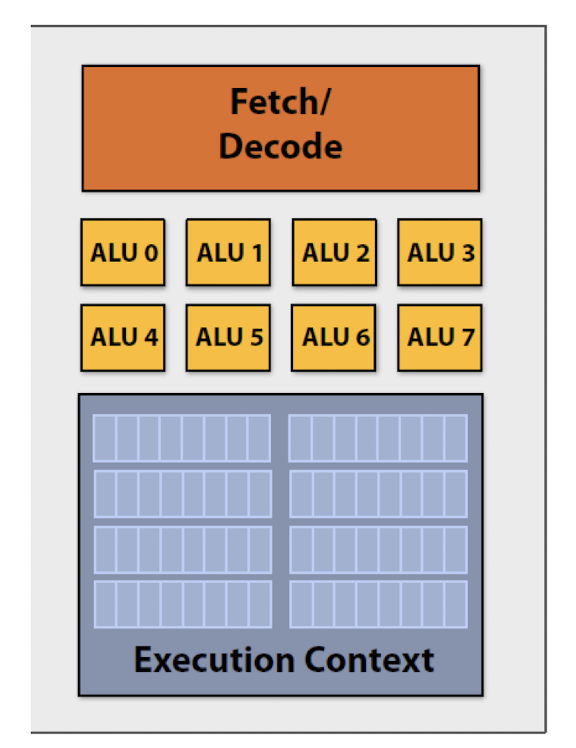
2.7. SIMD (Vector Processing)
잠깐! 모든 데이터에 대해 같은 연산을 수행한다면, 굳이 각 데이터에 대해 명령어를 따로 Fetch/Decode 할 필요가 있나??
SIMD: Single Instruction, Multiple Data
- 하나의 명령어로 여러 데이터를 동시에 처리한다 (like 벡터 연산)
- 예시: AVX, SSE, AVX-512
2.7.1. AVX2 예제
__m256i A = _mm256_load_si256((__m256i*)&a[i]);
__m256i B = _mm256_load_si256((__m256i*)&b[i]);
__m256i K = _mm256_load_si256((__m256i*)&k[i]);
__m256i C1 = _mm256_mullo_epi32(A, K);
__m256i C2 = _mm256_mullo_epi32(B, K);
__m256i C = _mm256_add_epi32(C1, C2);
_mm256_store_si256((__m256i*)&c[i], C);- __m256i: 256비트 정수형 벡터 → 32bit × 8개 동시 처리
- load, mul, add, store를 통해 CPU에서 SIMD 실행 가능
2.7.2. AVX 벡터 연산의 크기별 구성
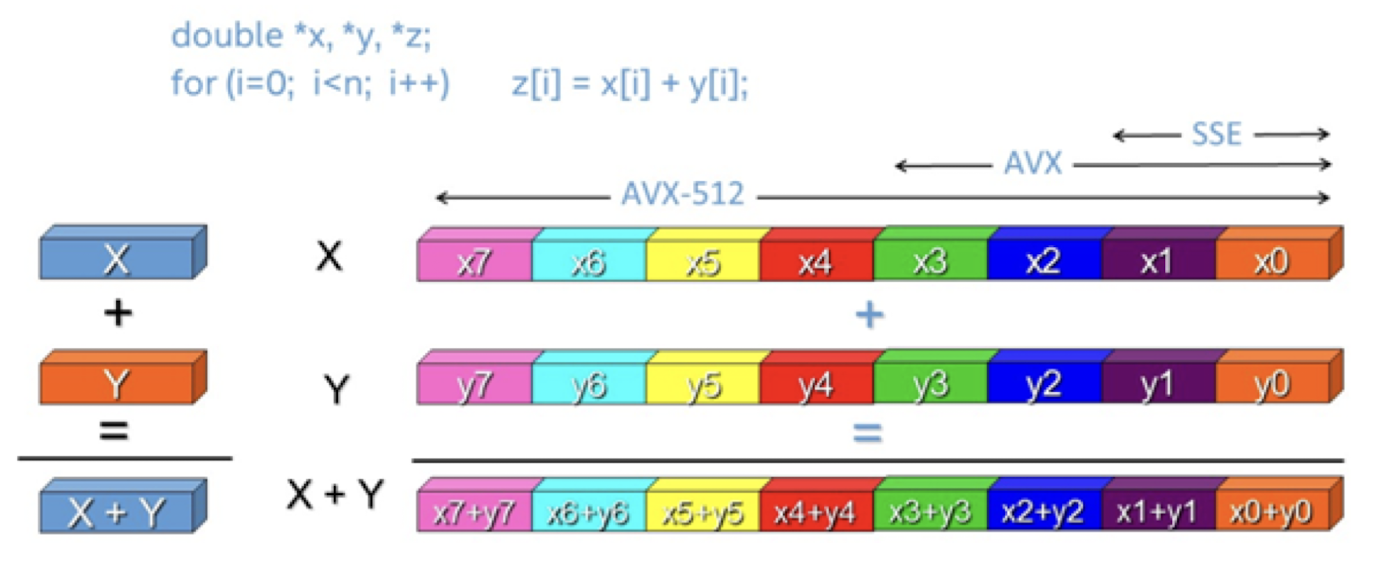
| 명령어 집합 | 비트폭 | 처리 데이터 |
|---|---|---|
| SSE | 128비트 | 4×32bit or 2×64bit |
| AVX2 | 256비트 | 8×32bit or 4×64bit |
| AVX-512 | 512비트 | 16×32bit or 8×64bit |
2.7.3. SIMD에서의 조건문 처리: Predication / Masking
일반적인 코드에서 조건 분기는 다음과 같이 이루어진다.
if (A[i] < 0) {
...
} else {
...
}SIMD에서는 하나의 명령어로 모든 연산을 동시에 실행하므로 명령어 분기 대신 마스크를 기반으로 조건 처리를 한다.
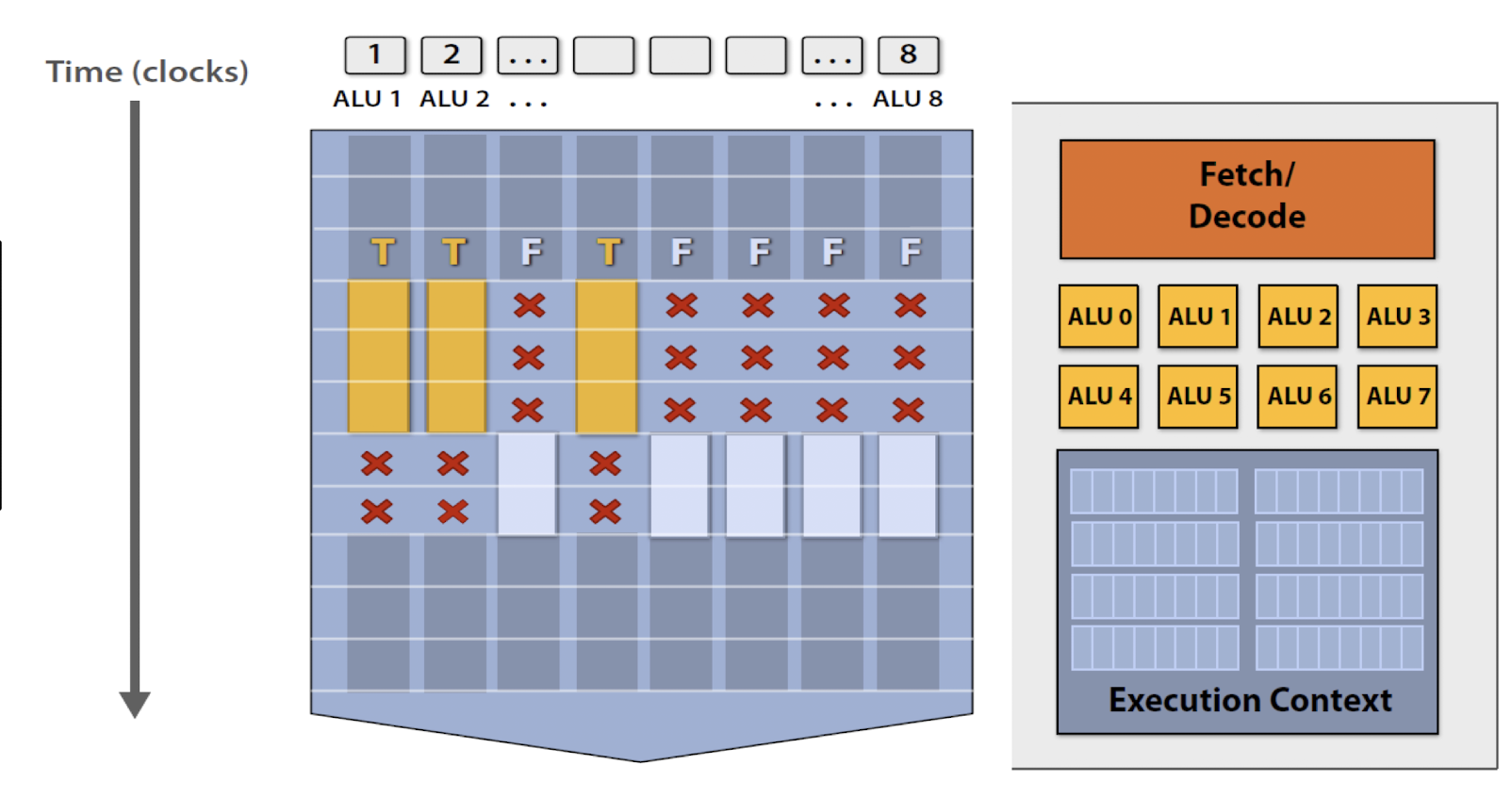
하지만 실질적으로 일부 연산만 유효하게 되기에, 유휴 계산이 발생할 수 있고, 이것이 GPU에서도 warp divergence 문제로 이어질 수 있다.
2.8. 병렬 아키텍처 분류 요약 (Flynn’s Taxonomy)
| 분류 | 설명 | 예시 |
|---|---|---|
| SISD | Single Instr. Single Data | 일반 스칼라 프로세서 |
| SIMD | Single Instr. Multiple Data | AVX, GPU |
| MIMD | Multiple Instr. Multiple Data | Multicore CPU |
| MISD | Multiple Instr. Single Data | Systolic array, TPU |
3. Matrix Multiplication
3.1. 일반적인 행렬 곱셈
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
for (int k = 0; k < N; k++)
C[i][j] += A[i][k] * B[k][j];행렬 에 대해 행렬곱 를 계산할 때 시간복잡도는 이다
3.2. Columnwise Block Striping
for (i = 0; i < N; i++)
for (j = p; j < N; j += P)
for (k = 0; k < N; k++)
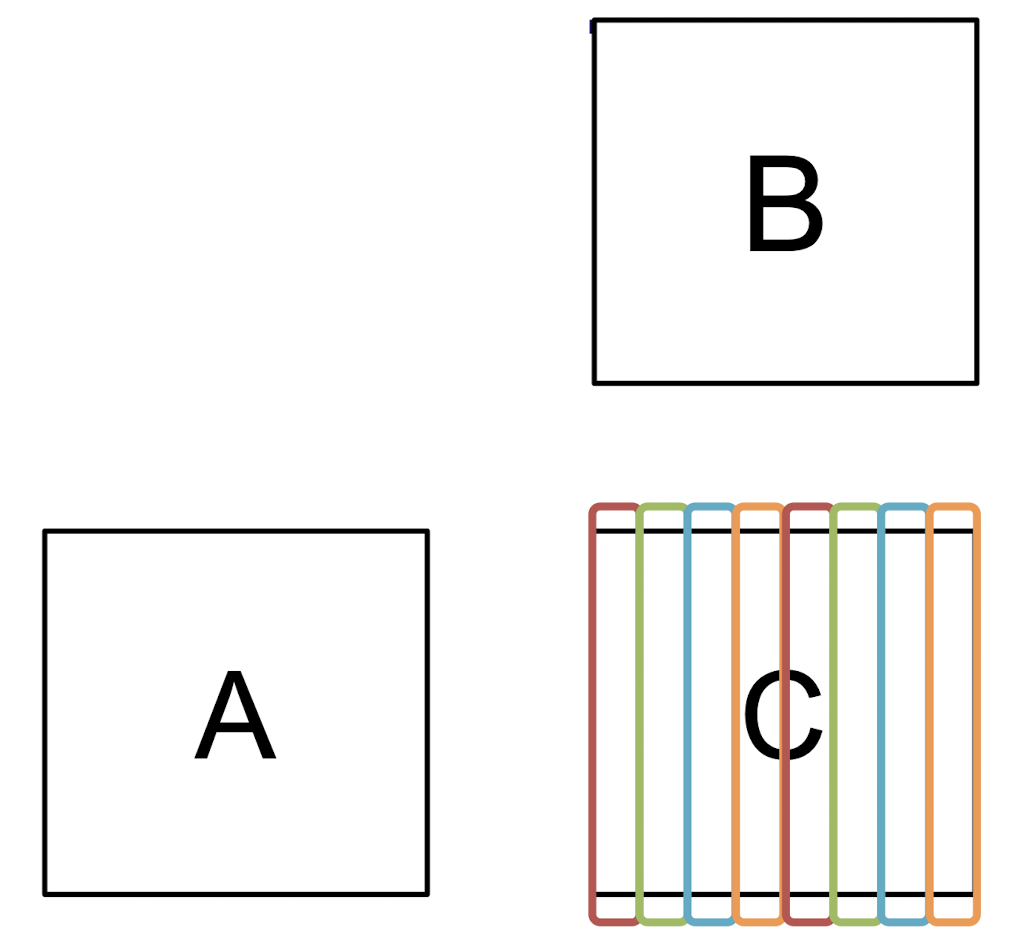
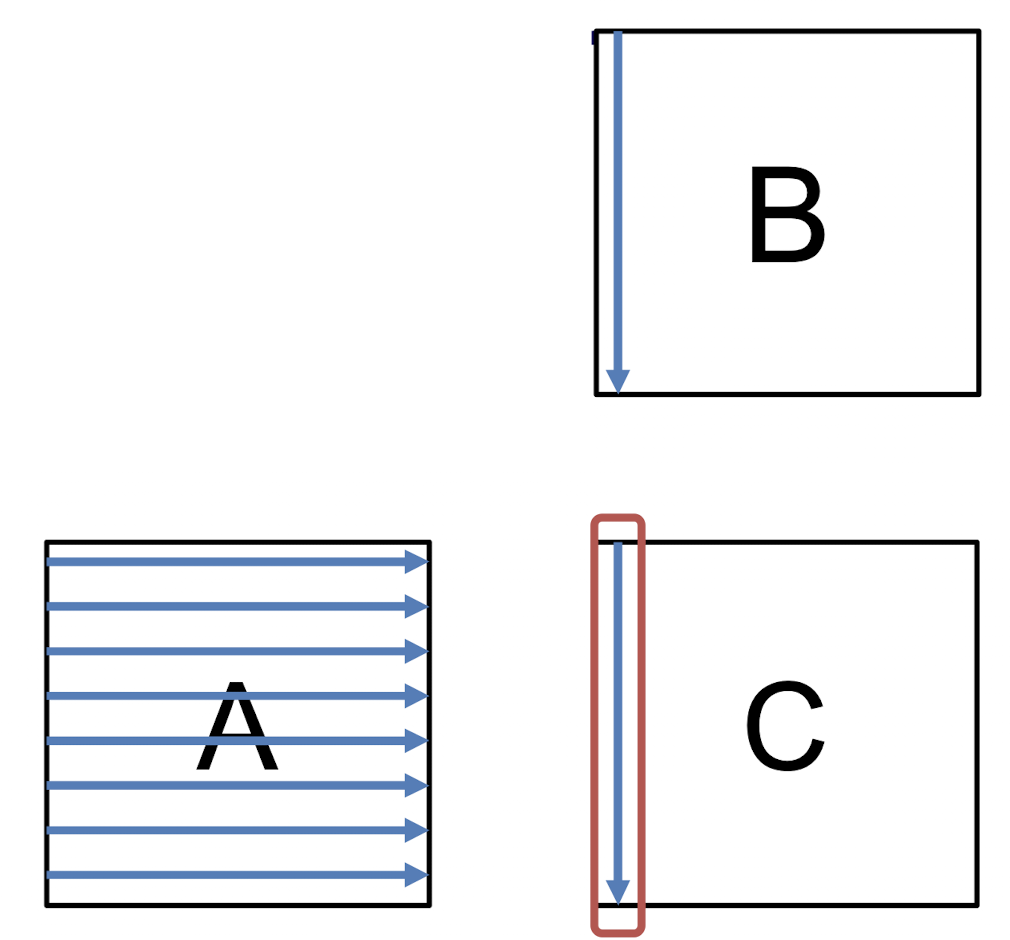
C[i][j] += A[i][k] * B[k][j];계산 대상인 의 각 열을 스레드 에 할당한다.
여전히 총 계산량의 시간복잡도는 이지만, 이는 각 개의 각 스레드 에 분배되며, 이들간의 계산이 중복되지 않고, 쓰기가 일어나는 메모리는 각 스레드간에 공유되지 않기에 Lock/Mutex가 필요없다.
따라서 실질적인 시간 복잡도는 이다.
하지만, 이러한 알고리즘은 cache Line의 특성에 의해 스레드 간 False Sharing 문제를 야기한다.
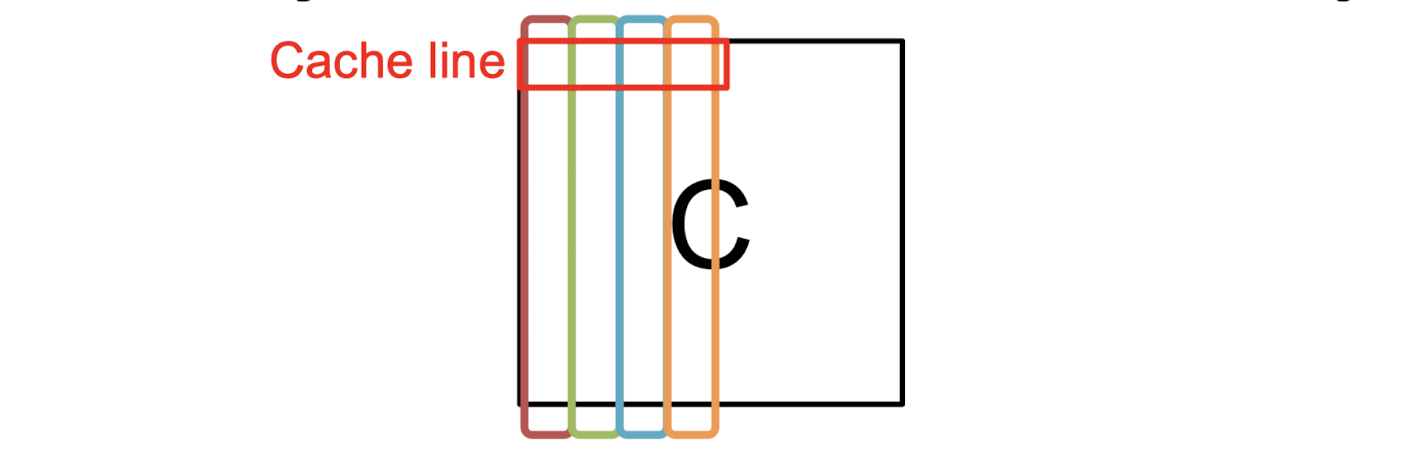
쓰기가 일어나는 의 각 열은 스레드에 의해 여러 코어에 분배되지만, 어떠한 스레드가 의 특정 주소에 값을 덮어씌우면, 해당 캐시라인은 캐시 일관성을 유지하기 위해 cache coherence protocol 에 따라 다른 코어에 로드된 캐시라인도 갱신되어 버린다.
이는 특히 실질적으로 1차원 배열 형태로 저장된 행렬의 메모리 구조상 빈번히 발생된다.
3.3. Rowwise Block Striping
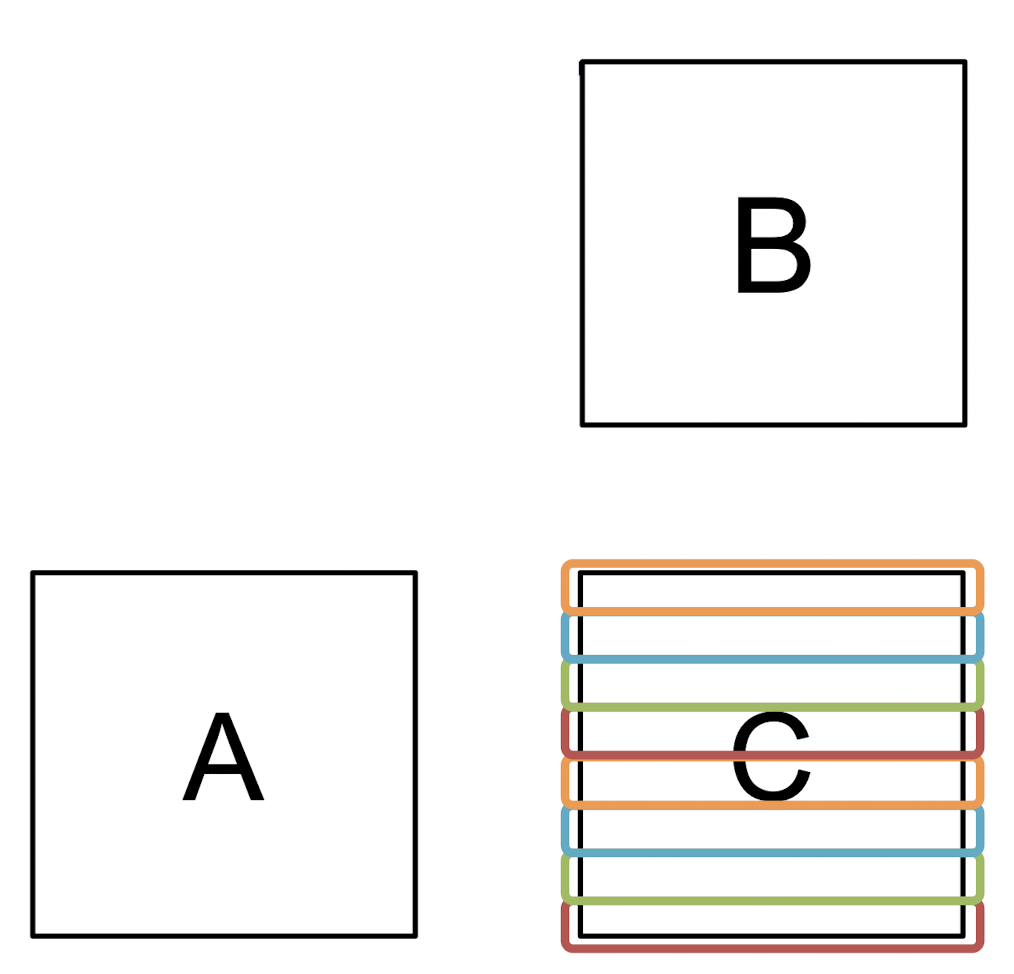
for (i = p; i < N; i += P)
for (j = 0; j < N; j++)
for (k = 0; k < N; k++)
C[i][j] += A[i][k] * B[k][j];이 또한 Columnwise Block Striping과 같은 시간복잡도 를 가진다.
한 스레드에 의해 쓰기가 일어나는 메모리 영역이 Rowwise 하기에 각 스레드간의 캐시라인 공유가 덜하여 False Sharing을 방지할 수 있다.
3.4. Cache Miss

캐시는 CPU에 가까울수록 용량은 작고 속도는 빨라진다.
가장 빠른 L1 캐시의 경우 통상적으로 32KB~64KB의 크기를 가지는데, 우리가 주로 계산하는 32bit = 4Byte의 부동소수점 float 에 대해서 8K~16K의 수용성을 가짐을 알 수 있다.
(실제로는 데이터 헤더 등으로 인해 더 작지만 여기서는 고려하지 않겠다)
이는 float 자료형에 대해 의 행렬 의 행렬을 포함할 수 있으며, 실질적으로 의 행렬을 모두 저장해야 하기에 각 행렬이 의 크기일 때 L1 캐시 안에 모두 수용된다.
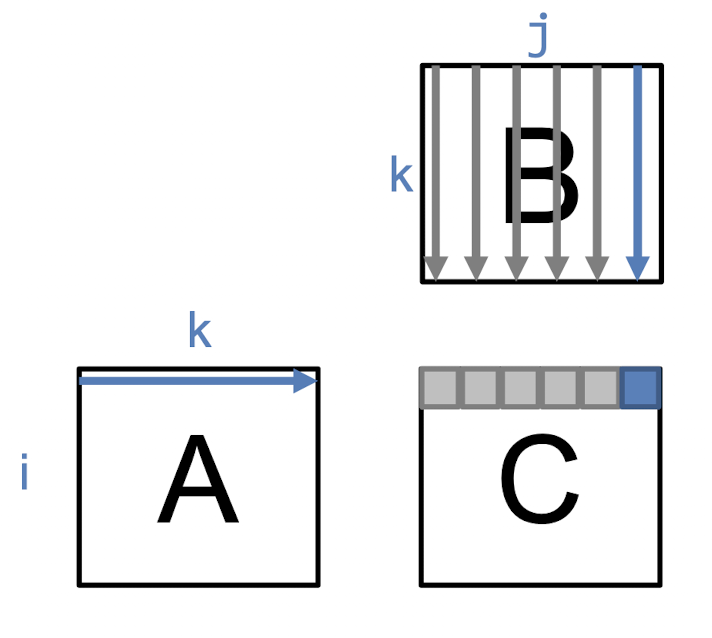
로 를 모두 L1 캐시에 담을 수 없을 때 행렬 계산과정에서의 캐시 미스는 다음과 같다
- 의 행을 처음 cache_line 크기만큼 읽을 때 cold miss, 이후 의 각 열에 대해 모두 all hit 번 Read
- 의 cache_line 크기만큼 건너뛰는 열의 행 요소를 읽을 때마다 전부 cold miss 번 Read
- 의 요소 하나를 읽고, 연산결과를 저장 11$ 번 Write
- 의 다음 행을 처음 읽을 때 cold miss, 이후 의 각 열에 대해 전부 all hit 번 Read
- 의 각 열을 읽을 때 전부 capacity miss 번 Read
- 의 대상 요소가 cache_line을 벗어날 때마다 읽고, 연산결과를 저장 번 Read, 번 Write
위의 과정을 개의 행에 대해 반복하면 총 캐시 접근횟수는 다음과 같다.
- 번 Read
- 번 Read
- 번 Read
- 번 Write
하지만, 이것은 가 캐시에 각 행의 캐시라인을 전부 담을 수 있을 만큼 이 클 때를 가정한 상황이다. 일반적으로 캐시라인의 크기는 float 16개를 담을 수 있는 64B로, 이를 기준으로 계산하면
위 조건이 만족될 때 우리가 구한 캐시 접근 횟수가 성립한다.
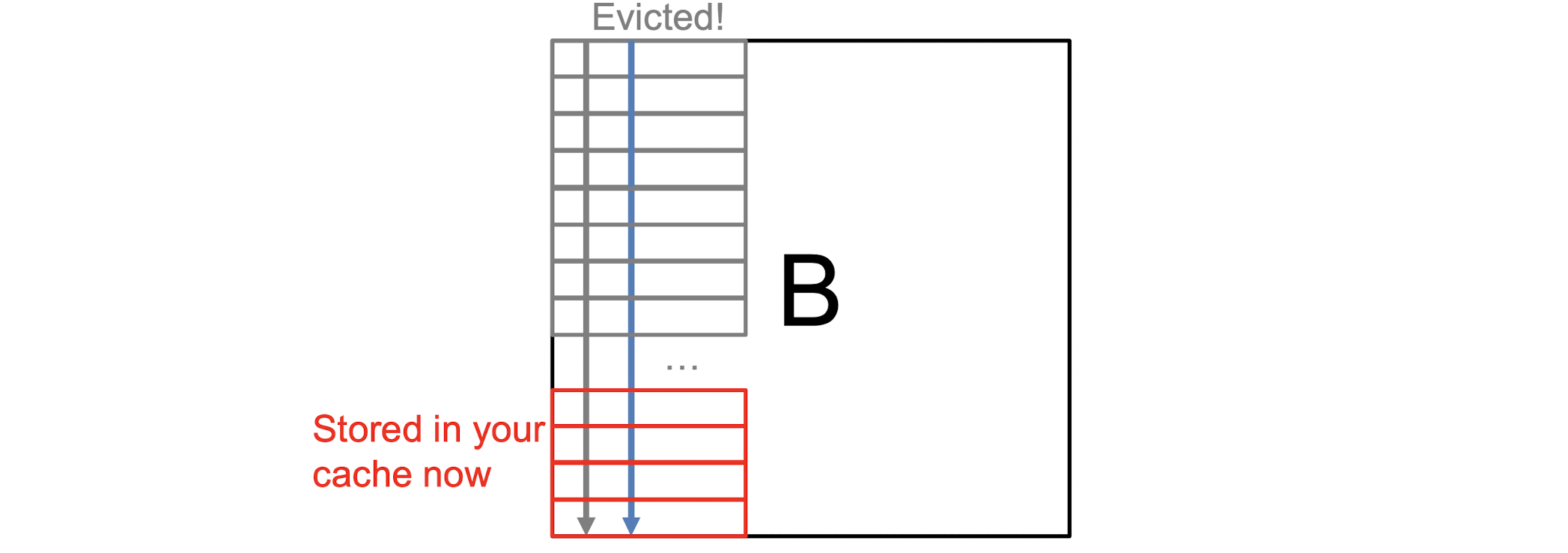
해당조건을 만족하지 못하면 의 뒷부분 행을 읽을 때 미리 읽었던 캐시라인이 덮어씌워지고 이는 다음 열을 읽을 때 기존에 읽어두었던 캐시라인을 재활용하지 못한다는 것을 의미한다. 이 경우 에 의한 캐시 접근횟수는 이 된다.
- 번 Read
- 번 Read (when , else, )
- 번 Read
- 번 Write
여기서 끝이 아니다.
만약 이 의 배수 꼴로 나타나면 n-way Set-Associative 에서 문제가 발생한다.
에서 Load하는 메모리의 Set Index는 다음의 공식으로 구하는데
일반적인 에서 일 경우 모든 행의 요소가 다른 행의 요소와 같은 Cache Set에 몰리게 된다. 이 경우 의 열의 요소를 순차적으로 읽을 때 실질적 캐시 크기는 캐시라인이 8개인 한 개의 Cache Set 크기 (여기서는 )가 되기에 의 Read 조건은 더 열악해진다.
- 번 Read (when , else, )
이렇게 일 때에는 패딩을 추가하여 모든 행이 같은 캐시라인에 몰리는걸 막아야 한다.
3.5. Transpose
일 때 생기는 문제를 해결하기 위해 고안할 수 있는 방법 중 하나는 의 전치 행렬을 가지고 연산하는 것이다.
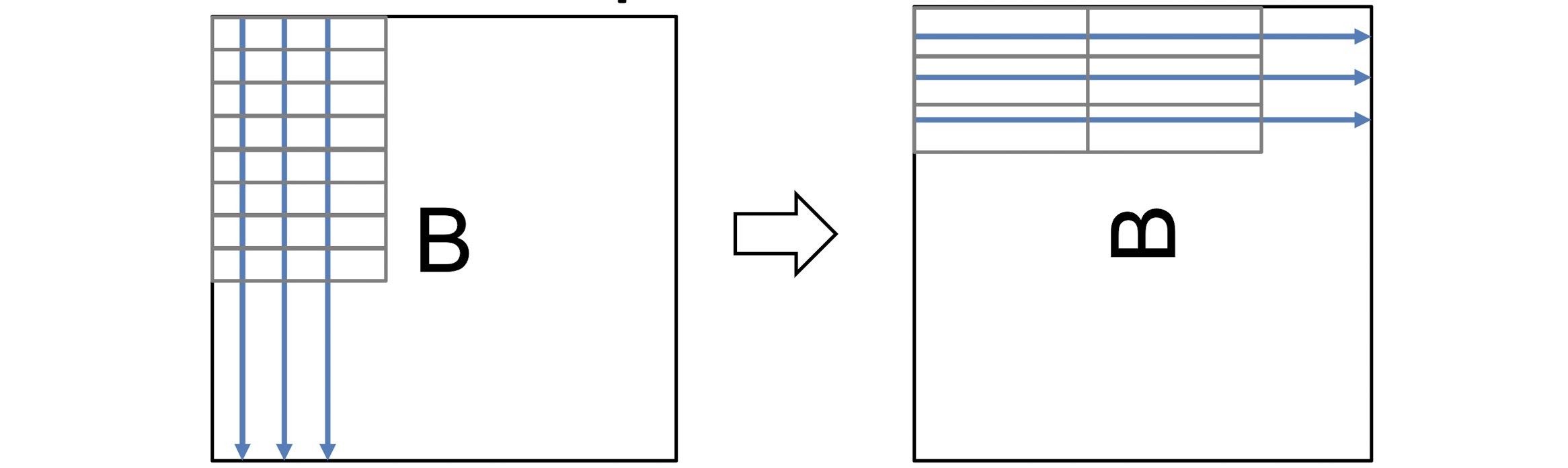
위 그림처럼 를 전치행렬로 만들고 여기에 접근하면 기존의 열 방향 순회 접근이 행 방향으로 바뀌며 와 같이 하나의 cache_line의 여러 요소에 연속적인 접근이 가능하게 된다.
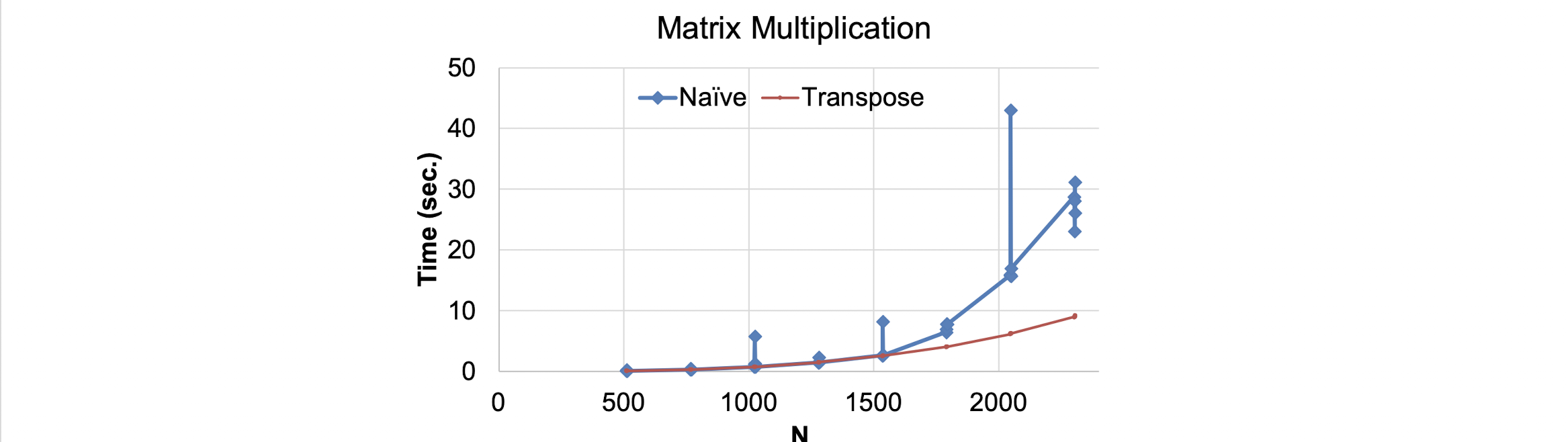
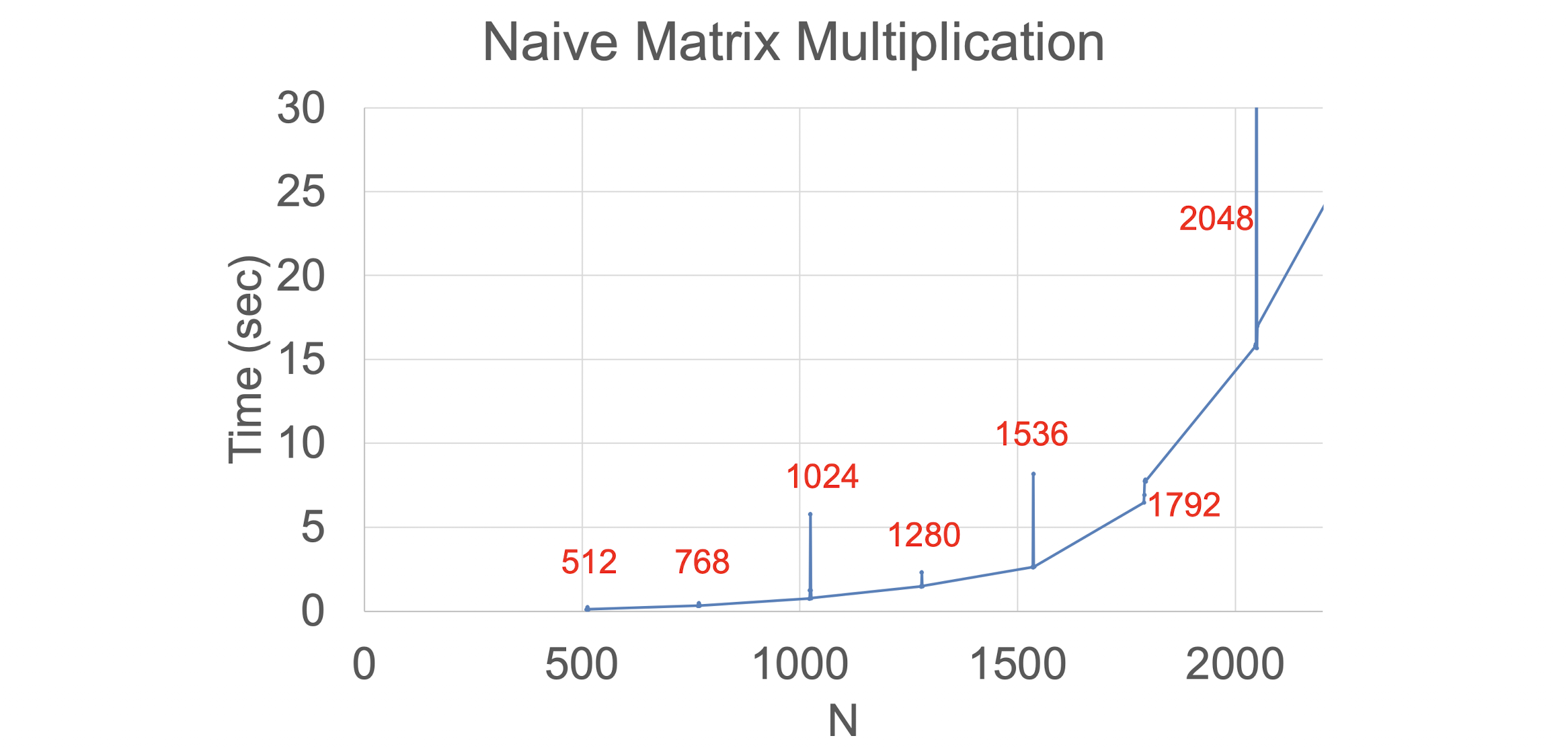
또한, 위의 그래프를 보면 N이 일정 수준 이상 커질 때 단순히 피크때의 캐시미스 폭발을 방지하는 것을 넘어 전체적인 성능 격차가 벌어지는 것을 볼 수 있는데 이는 위에서 확인한 조건인 $L1 \geq 16N$ 등 $L1, L2, L3$ 캐시 단의 접근 로직과 메모리 연속성, 예측성 등의 이유가 있다.
| 효과 | 설명 |
|---|---|
| Conflict Miss 감소 | 2ⁿ size에서 발생하는 set 충돌 방지 |
| Spatial Locality 개선 | 연속 접근을 유도하여 캐시 적중률↑ |
| Prefetch 최적화 | CPU가 연속 패턴 예측 가능하게 만듦 |
| Capacity Miss 감소 | 실제 필요한 B block만 캐시에 유지 가능 |
3.6. Blocked Matrix Multiply
행렬의 행렬곱은 부분행렬 행렬곱들의 합으로 표현할 수 있다.
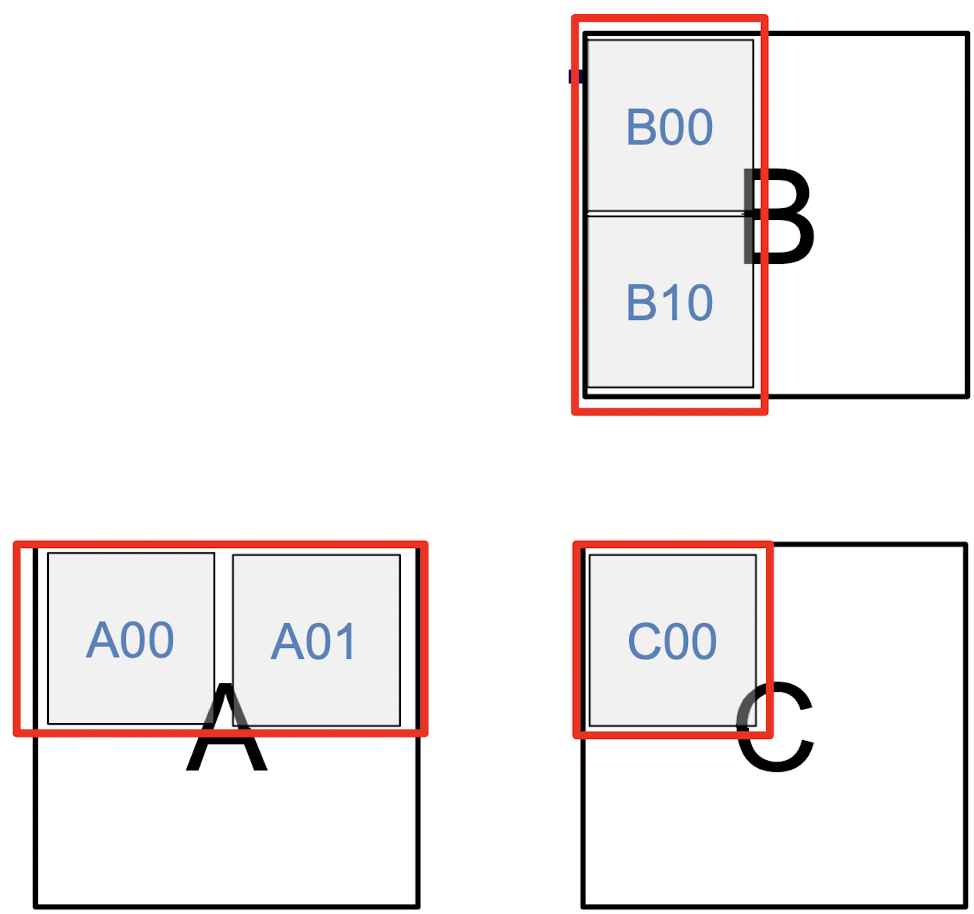
이렇게 분할했을 때 각 부분행렬(Block)의 크기를 라 하면 이때 대표적으로 부분행렬곱 행렬 를 계산하기 위한 메모리 엑세스 횟수를 계산하면 다음과 같다.
- 번 Read
- 번 Read
부분행렬의 크기가 일 때, 의 한 부분행렬을 계산하기 위해 필요한 메모리 엑세스는 부분행렬의 각 축의 개수가 이므로 각각
- 번 Read
- 번 Read
- 번 Read
- 번 Write
의 액세스가 필요하고, 따라서 전체 행렬 에 대한 연산에서는
- 번 Read
- 번 Read
- 번 Read
- 번 Write
의 메모리 엑세스가 필요함을 알 수 있다. 이 식에서 부분행렬의 크기 가 클수록 에 대한 메모리 엑세스 횟수가 낮아짐을 알 수 있다.

3.7. Make L2 Cache-Friendly
우리는 캐시 이외에도 , 캐시도 가지고 있다. 따라서 이러한 캐시 크기에 맞게 행렬을 부분행렬들의 부분합으로 계속 분리해나갈 수 있고 이 매우 클때에는 이에 따른 약간의 이점을 얻어갈 수 있다.
단, 여기서 캐시는 코어에 독립적이지 않고 전체 코어가 공유하는 캐시이기에 각 스레드가 캐시를 점유하지는 않는다.
대신 여러 스레드 간에 접근하는 메모리가 지역성을 잃어버리게 되면 에 로드되는 캐시가 계속 바뀌어 캐시한 메모리에 대한 재사용성을 잃어버릴 수 있고, 각 스레드가 계산하는 부분행렬 블록도 너무 크면 메모리가 가득 차 Cache miss가 발생할 수 있기에 블록 사이즈를 잘 조절해야한다.
3.8. More Things to Optimize
지금까지 살펴본 방법 이외에도
- Loop reOrdering
- Loop Unrolling
- Partition Strategy
- Vector Proceessing (SSE, AVX, …etc)
- Strassen/Winograd Algorithm
등 다양한 전략을 활용하여 행렬 연산을 최적화 할 수 있다.
4. Cuda MGP
4.1. CUDA 개요
NVIDIA GPU를 위한 병렬 프로그래밍 SPMD(Single Program Multiple Data) 모델로 많은 thread들이 프로그래머가 작성한 동일한 함수(kernel)를 병렬로 실행할 수 있도록 지원한다.
4.2. 실행 모델 (Execution Model)
GPU → SM → Grid → Block → Warp → Thread → Kernel
4.2.1. GPU (Graphical Processing Unit)
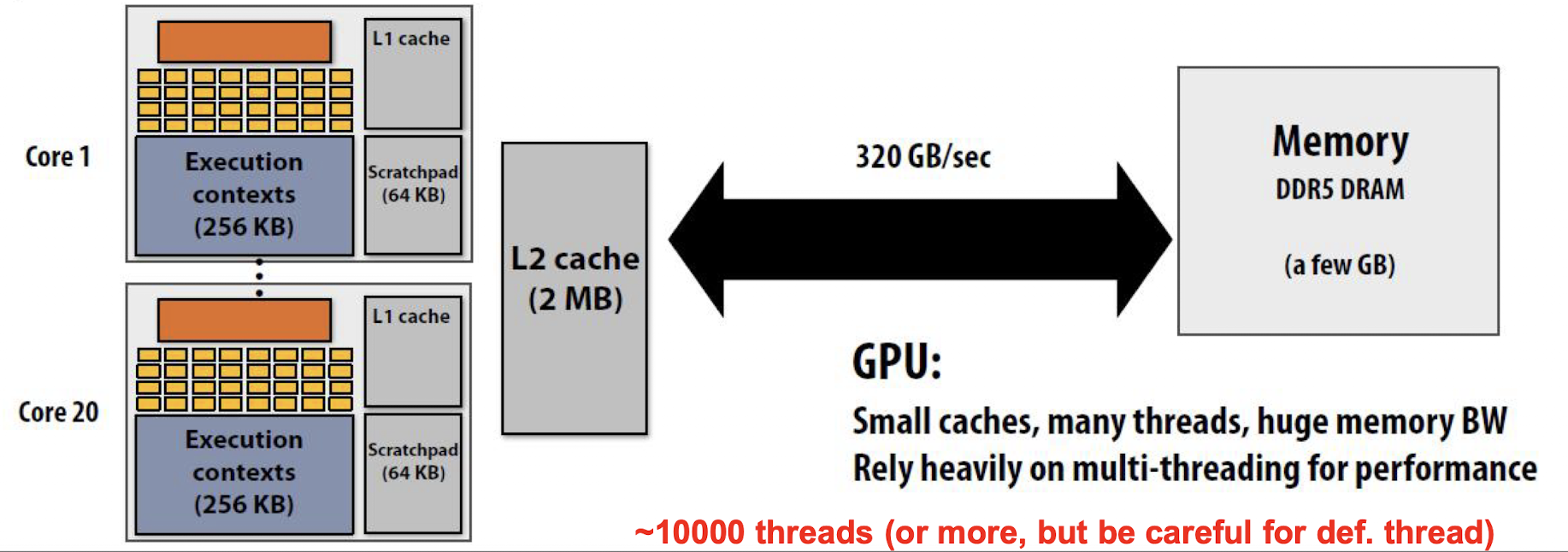
GPU는 CUDA 연산이 수행되는 전체 장치 자체를 지칭하며, 여러 개의 SM (Streaming Multiprocessor)으로 구성된다.
CUDA kernel을 실행하기 위한 모든 자원을 가지고 있다 (global memory, L2 cache 등)
4.2.2. SM (Streaming Multiprocessor)
GPU 내부의 연산 유닛 묶음으로 GPU 병렬성의 기본 단위이다. (단순히 말해 코어이다)
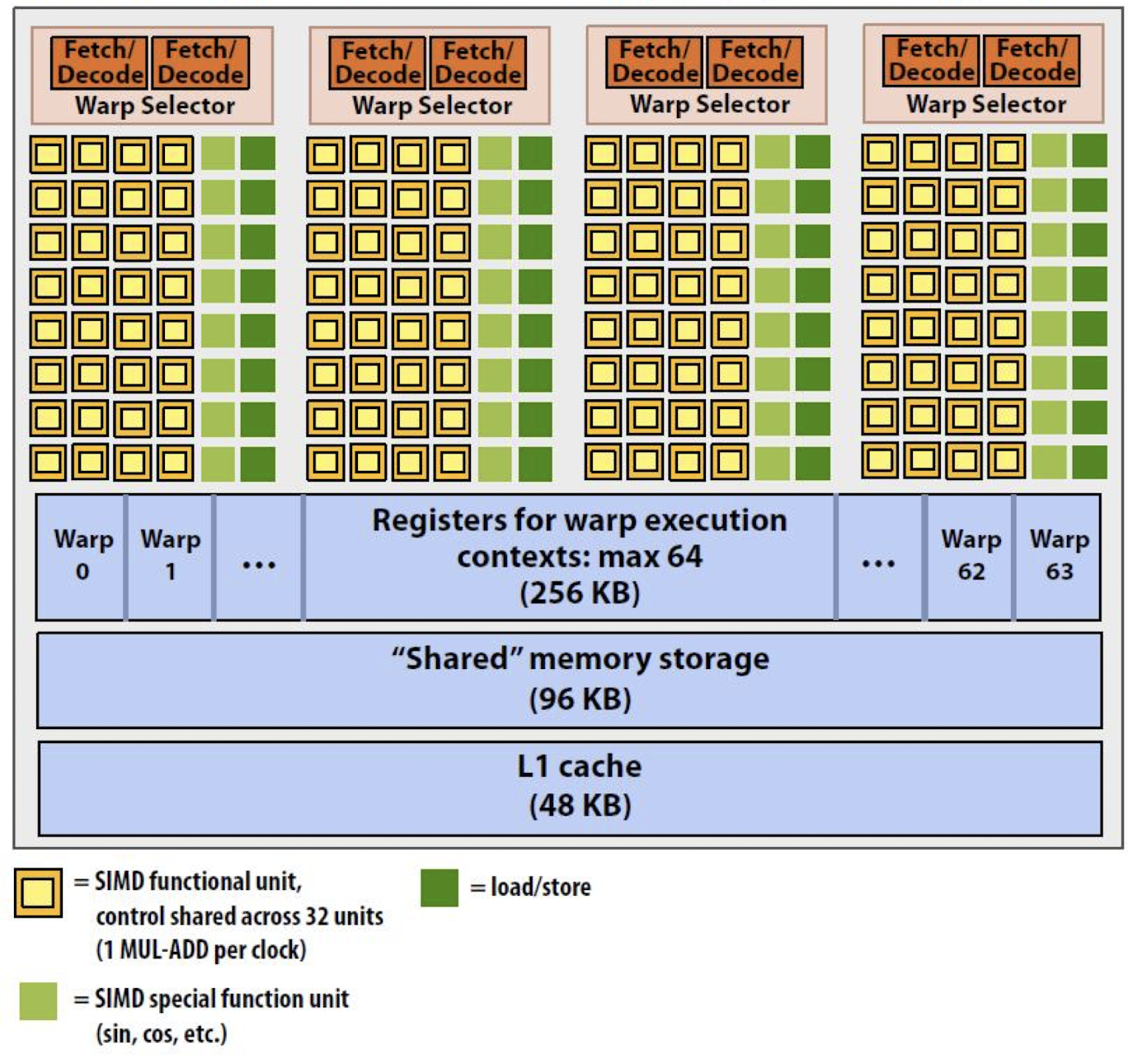
GPU 내부에는 여러 SM이 독립적으로 동시에 동작하며 각 SM은 자체적으로
- ALU (산술 연산 유닛)
- Special Function Unit (sin, cos 계산용)
- Warp Scheduler
- Shared Memory
- L1 Cache
- Register 파일
과 같은 요소를 가지고 있으며 스레드가 실행되는 실질적 장소이다.
SM 하나는 동시에 여러 Block을 실행할 수 있음 (자원의 여유가 있을 때)
4.2.3. Grid (그리드)
CUDA에서는 커널 함수를 호출할 때 Block이라는 단위로 호출하는데, 이러한 Block들을 그룹으로 분할하여 한번 더 감싸는 가상의 집합이다.
커널을 실행할 때에는 kernel<<<gridDim, blockDim>>>(...) 의 형식으로 호출하는데, 여기서 gridDim 이 Block을 어떤 사이즈로 분할하여 그룹할지에 대한 정보를 담고 있다. 이러한 그리드는 1D, 2D, 3D로 구성할 수 있다.
블럭이 수용할 수 있는 스레드의 수가 제한되어 있기에 이보다 많은 데이터를 처리하기 위해서는 블럭 또한 많이 필요할 수 있다. 이러한 블럭을 관리하기 위한 논리적(추상적) 개념이 그리드이다.
4.2.4. Block (블럭)
CUDA에서 SM에서 실행되는 작업 단위의 최소 단위이며 하나의 블럭은 무조건 하나의 SM에만 할당된다. (단, 하나의 SM에서는 SM의 독립 자원이 허락하는 내에서 여러 블럭을 실행할 수 있다.)
같은 블럭 내 스레드끼리는 shared memory 공간을 공유하여 통신할 수 있지만, 블럭 간에는 직접적인 통신이 불가능하며, 스레드에서 실행되는 명시적인 순서 또한 존재하지 않는다. (하나의 SM에 여러 블럭이 할당되어 있더라도 각 블럭은 Warp로 분리된 후 순서 없이 실행 준비가 되는대로 Warp 단위로 스케줄링 된다.)
하나의 블럭당 최대 1024개의 스레드를 수용할 수 있으며 통상적으로 256개의 스레드를 포함한다.
4.2.5. Warp (와프)
블럭 안의 스레드를 32개씩 묶은 단위를 Warp라고 한다.
SM의 Warp Schedular에 의해 스케쥴링 되는 단위이며 SIMD의 원칙을 살려 같은 Warp 내의 모든 스레드는 같은 연산을 실행할 때 최적의 효율을 낸다.
4.2.6. Thread (스레드)
커널 함수의 한 인스턴스를 맡아 실제 연산을 수행하는 최소 단위를 스레드라고 한다.
이러한 스레드는 자신만의 레지스터와 로컬 메모리를 가진다.
4.2.7. Kernel (커널)
프로그래머에 의해 작성되어 GPU의 여러 스레드에 분산되어 동시에 실행되는 CUDA 전용 함수이다.
__global__ 로 선언되며 <<<gridDim, blockDim>>> 으로 실행된다.
4.2.8. Grid와 Block의 차이, 존재 이유
실질적으로 SM 단위로 배정되는 스레드의 집합이자 실행 단위인 Block과 달리 Grid는 이러한 Block들을 다시 한번 그룹화하는 논리적, 추상적인 단위이다.
하나의 블럭은 최대 1024개의 스레드만을 가질 수 있으나, 대규모 연산에서는 보통 수백만 개 이상의 스레드 연산이 필요하다. 따라서 블럭 또한 매우 많이 생성되기에 이 블럭을 논리적으로 관리하는 공간으로써 그리드를 사용하는 것이다.
또한, 블럭은 그 특성상 하나의 SM에 배치되어 실행되고, 다른 블럭과 통신이 불가능하다. 따라서 그리드는 다르게 말해 독립적 연산을 하는 블럭들을 묶어 전체 연산 영역을 표현하는 문제 전체의 논리적 표현을 도울 수 있다. 이는 상대적 위치만을 가진 threadIdx 의 한계를 넘어 blockIdx 를 통해 전체 연산 공간에서 스레드의 절대 위치를 계산하는데 유용하다.
(예를 들면, 3D 텐서와 이미지 등의 복잡한 연산에서 Block과 Grid를 3차원으로 Nested하게 배열할 수 있다.)
4.2.9. L2 Cache
GPU 전체에 걸쳐 공유되는 2차 캐시로 글로벌 메모리인 Device-RAM(DRAM)과 각 SM 사이에 위치하여 데이터 재사용과 메모리 대역폭 최적화를 담당한다. (프로그래머가 접근하지 못한다)
같은 데이터를 여러 블럭에서 접근하는 경우 블럭은 SM마다로 할당되기에 이들 중 한 블럭이 읽은 데이터가 L2에 위치하면 다른 블럭에서 DRAM까지 가지 않고 L2에서 재사용할 수 있다.
CPU에서는 이러한 공유 메모리(L3 캐시)를 Latency를 줄이는 입장에서 접근하지만, GPU에서는 Throughput을 높이는 입장에서 접근한다. 이는 GPU가 Latency를 줄인다기 보다는 이를 숨기는 방식을 취하기 때문인데, GPU는 수천 개의 스레드를 동시에 실행하기에 어떠한 스레드에서 Global Memory 액세스로 인해 Stall이 발생하면 단순히 다른 스레드를 대체 실행해서 Latency를 숨기는 것이다.
4.2.10. L1 Cache
L1 캐시는 각 SM에 장착되어 글로벌 메모리로의 액세스를 빠르게 하기 위한 자동 관리형 캐시다. 따라서 프로그래머가 관리할 수 없다.
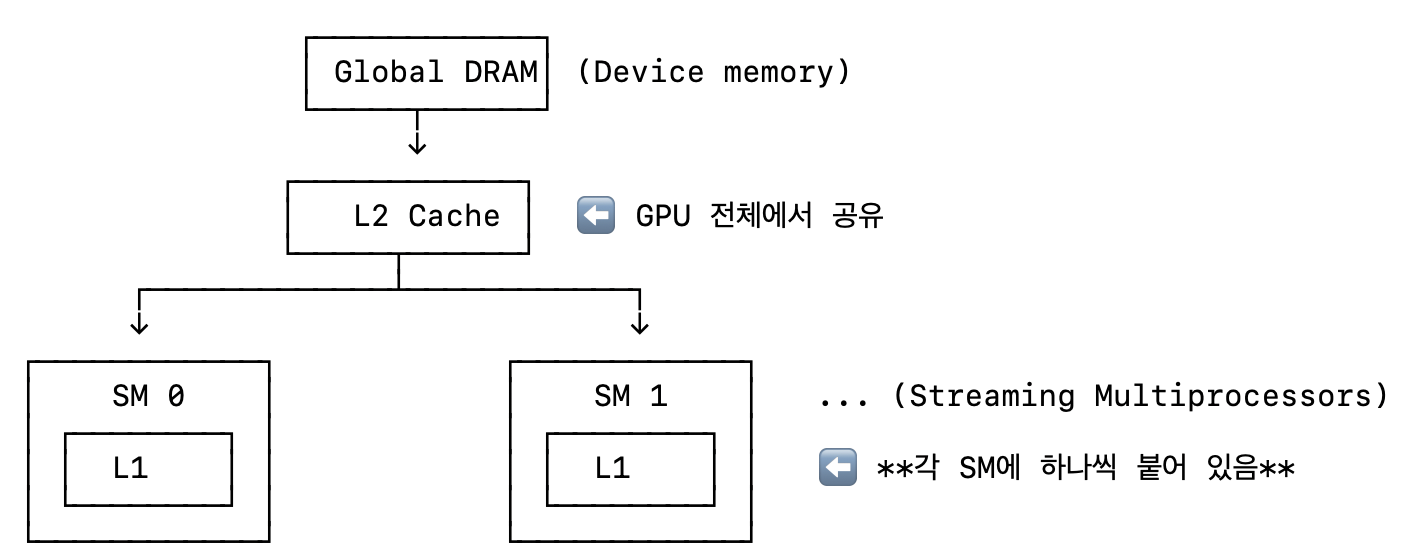
L2 캐시가 SM 간의 데이터 재사용을 통해 최적화를 한다면 L1 캐시는 SM-DRAM의 글로벌 메모리 액세스를 캐싱하여 Latency를 줄인다. (Shared Memory보다는 느리다)
L1 캐시는 대체로
- 스레드들이 연속된 주소에 접근할 때: Spatial Locality Hit
- 반복적으로 같은 배열에 접근할 때: Temporal Locality Hit 의 상황에서 성능을 비약적으로 향상시킨다.
반대로 순차적이지 않은 Random Access, 1이 아닌 일정 간격의 index로 건너뛰는 Stride Access에서는 성능 활용이 감소한다.
4.2.11. Coalesced Memory Access (메모리 병합 접근)
하나의 Warp 내에서 thread들이 글로벌 메모리에 접근할 때, 이들이 연속적이고 정렬된 주소에 접근하면 GPU는 여러 개의 접근을 하나의 Memory Transaction으로 병합해서 처리한다.
이를 Coalescing (메모리 병합 접근)이라고 한다.
글로벌 메모리 액세스는 비용이 매우 비싸기에 Coalescing을 통해 대역폭을 절약하고 액세스 횟수를 줄이며 L1, L2 캐시의 히트율을 높인다. 이러한 조건은 다음과 같다.
| Warp 내 thread가 | 32개 |
|---|---|
| 접근 주소가 | 연속적이고 정렬됨 (stride = 1) |
| 시작 주소 | L1/L2 캐시라인 크기에 align됨 (예: 128B 기준 주소) |
따라서 Stride Access를 없애고 다차원 행렬에 대해서는 스레드를 Rowwise하게 배치하는 것이 효과적이다.
4.2.12. Shared Memory (공유 메모리)
Shared Memory, 다른 말로 Scratchpad Memory는 프로그래머가 명시적으로 관리하는 고속 로컬 메모리이다. 캐시 수준의 속도를 가지고 한 블럭 내의 모든 스레드가 접근 가능하여 스레드 간 협업, 데이터 재사용을 위해 사용된다.
일반적으로 캐시는 하드웨어가 직접 관리하는데에 반해 GPU의 Shared Memory는 다음과 같이 프로그래머가 명시적으로 데이터를 로드하고 지워야한다.
__shared__ float tileA[BLOCK_SIZE][BLOCK_SIZE];Shared Memory는 32개의 bank라는 단위로 구성된다. (CPU Cache의 Set-Associative를 생각하면 편하다)
bank의 수가 32개인 이유는 한 Warp의 스레드 개수가 32개이기 때문이며, 각 bank 안에는 연속적이지 않게 4B, 8B 단위로 정렬된 주소 집합이 들어있다. Shared Memory에 대한 액세스가 발생하면 스케줄링과 파이프라이닝을 통해 Warp 단위로 순차적으로 이루어지게 된다.
이러한 Shared Memory를 주의해야 할 점들이 있다.
- Bank Conflict Shared Memory 액세스는 Warp단위로 처리되기 때문에, 이상적인 경우 즉 32개의 모든 스레드가 서로 다른 32개의 뱅크의 메모리 주소에 접근할 경우 문제가 없다. 또한, 여러 스레드가 같은 주소에 접근할 때에도 문제가 없는데, 이는 하나의 스레드가 값을 bank에서 값을 읽어온 뒤 다른 스레드에게 Broadcasting 하기 때문이다. 하지만 여러 스레드가 같은 bank에 위치한 다른 주소에 접근할 때에는 스레드들이 같은 bank에 접근하면서도 서로 다른 값을 읽어와야 하기에 다른 스레드가 bank에 접근해 값을 읽는 동안 나머지 스레드들이 기다려야하는 직렬화가 발생한다. 이는 많은 스레드를 동시에 처리하는 GPU 연산의 특성과 위배되기에 병목 현상을 발생시킨다.
- Occupancy 감소 (자원 과다 사용) Shared Memory는 한 SM에 하나만 할당되는 자원이다. 따라서 특정 블럭이 Shared Memory를 과다하게 소비하면 Occupancy가 감소해 SM에서 동시 실행 가능한 Block의 수가 줄어든다. 이는 Warp 수를 감소시키고 Occupancy를 떨어트려 Latency Hiding 효과를 감소시킴으로써 전체 GPU의 Throughput을 감소시키는 원인이 된다.
- Race Condition
CPU의 스레드에서와 마찬가지로 GPU 또한 Shared Memory에 여러 스레드가 Read/Write을 하면 Race Condition이 발생한다. 이를 위해
Atomic이나syncthreads()등의 동기화 문법을 적절히 사용해야 한다.
특히 Bank Conflict의 경우 CPU의 Set-Associative 전략과 마찬가지로 인 행렬 구조에서 단순히 threadIdx.x 를 stride로 액세스할 경우(즉, 열방향 순차 접근) 모든 스레드의 Shared Memory Access가 하나의 bank로 몰릴 수 있다. 이 경우 적절한 padding을 추가하여야 한다.
최신 프로세서에서는 L1 캐시와 Shared Memory가 물리적으로 통합되어 있으나 소프트웨어적으로는 분리되어 있어 cudaFuncSetCacheConfig() 으로 각 자원의 필요 비율에 따라 조정이 가능하다.
실제로 한 SM에 여러 블럭이 실행될 수 있듯이, Shared Memory도 각 블럭별로 프로그래머가 명시한 만큼의 공간을 할당받는다. 이들은 안전하게 동적 런타임에 자동으로 분할되어 할당되며, 그렇기에 한 SM에 여러 블럭이 실행되더라도 블럭 간 Shared Memory 접근의 충돌이나 공유는 불가능하다.
4.2.13. Warp Execution Context
GPU의 SM이 하나의 Warp를 실행하기 위해 필요한 모든 상태 정보(registers, PC, mask 등)의 묶음을 Warp Execution Context라 한다. 내부 구성요소는 다음과 같다.
| 구성요소 | 설명 |
|---|---|
| Program Counter (PC) | 해당 warp가 실행 중인 명령어의 주소 |
| Predicate Register / Mask | 조건 분기를 위한 활성화 마스크 (warp divergence 제어용) |
| Register State | 32개 thread 각각의 레지스터 값 (warped register file) |
| Thread Mask | 어떤 thread가 현재 활성화되어 있는지 표시 |
| Memory Dependency State | global/shared memory 접근 대기 여부 |
이들은 모두 하드웨어적으로 저장되어 있어 즉시 교체 가능하며, 이를 Zero-Cost Context Switching이라 부른다.
4.2.14. Constant Memory
Constant Memory는 Shared Memory와 Global Memory 사이에 위치하는 GPU의 읽기 전용 메모리 공간으로, 모든 SM에서 같이 접근할 수 있다. CUDA에서 선언한 __constant__ 변수에 해당하며 모든 thread에서 읽을 수 있지만 host에서만 값을 쓸 수 있다.
| 항목 | 설명 |
|---|---|
| 읽기 가능 위치 | 모든 thread에서 접근 가능 |
| 쓰기 가능 위치 | 오직 **CPU(host)**에서만 가능 (cudaMemcpyToSymbol) |
| 최대 크기 | 64KB (65536 bytes) per device (기본값) |
| 속도 | Global memory보다 훨씬 빠름 (캐시 지원) |
| 캐시 방식 | 전용 L1 constant cache (broadcast 방식 지원) |
Warp 단위로 브로드캐스팅 되기 때문에 Warp의 모든 스레드가 같은 주소의 값을 읽을 때 최고의 효율을 보여준다.