이 포스트는 연세대학교 컴퓨터과학과 22학번 박철우 학우의 기여로 작성되었다.
1. Network Flow
이때까지 보았던 구간 스케줄링 문제나 최대 지연 시간을 최소화하는 스케줄링 문제들은 알고리즘 설계 방법론을 설명하기 위한 것이라면, 지금부터는 실제 다양한 응용 분야에서 발생하는 네트워크 흐름 문제(Network Flow Problem)를 알아보고 해결해보고자 한다.
1.1. 도입
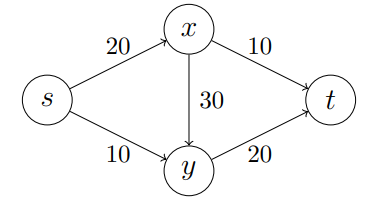
$\bigtriangleup$ Figure 1: A pipeline network
위의 그림과 같이 각각의 도시들 간 파이프라인 네트워크가 설정되어 있다고 가정하자. 이때, S 도시는 X 도시에 단위 시간당 최대 20까지 보낼 수 있으며, X 도시에서 T 도시에는 단위 시간당 최대 10까지 보낼 수 있다. 이렇게 되었을 때, S 도시에서 T 도시까지 단위 시간당 보낼 수 있는 최대 원유의 양은 얼마일까?
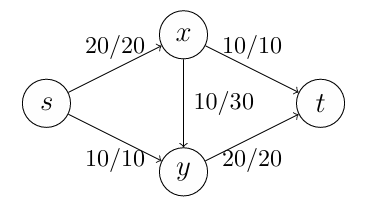
$\bigtriangleup$ Figure 2: Sending 30 units of oil
위 그림과 같이 S 도시에서 T 도시까지 단위 시간당 최대 30까지의 원유를 보낼 수 있다. 이와 같이 digraph와 각각의 arc에 대한 최대 용량이 주어졌을 때, 시작 지점에서 목표 지점까지 보낼 수 있는 최대 양을 출력하는 알고리즘을 설계해보자.
Digraph
Digraph는 노드와 방향이 있는 간선(edge)으로 구성된 그래프(Directed Graph)로 다음과 같은 요소들을 가지고 있다.
- Vertex (꼭짓점): 그래프의 개체 또는 요소를 나타내며 노드의 역할을 한다.
- Arc (호): 두 Vertex 사이의 방향을 가진 연결이며 방향이 있는 간선(edge) 역할을 한다. Digraph는 방향성을 가진 관계를 모델링하는 데 주로 사용되며 이번 챕터에서 다룰 Network Flow에서 주로 사용되는 Graph이다.
1.2. 문제 정의
1.2.1. Definition 1
Flow network는 각 간선이 음수가 아닌 용량(non-negative capacity)을 가진 Digraph이다. 이때 간선 e의 용량을 라고 표기한다. 또한, Flow network는 소스 노드(시작 노드)인 와 싱크 노드(도착 노드)인 로 구성되어 있으며 이를 제외한 다른 노드들은 모두 내부 노드라고 정의한다.
그리고 다음과 같은 가정을 세운다.
- 어떤 간선도 소스 노드()로 들어오지 않는다.
- 모든 노드는 적어도 하나의 간선을 가진다.
- 모든 용량(Capacity)은 음이 아닌 정수이다.
왜 모든 용량을 정수로 가정할까?
만약 우리가 그래프 내 모든 간선들의 용량을 유리수로 가정한다면 컴퓨터는 용량들 간의 연산을 위해 모든 용량들을 통분한 후 분자들만으로 계산을 할 것이다. 이때 모든 용량을 정수로 가정한 연산이랑 같게 되며 마지막 부분에 공통분모로 나누어 주기만 하면 되므로 정수로의 가정은 큰 문제가 되지 않는다. 만약 모든 용량이 무리수라면 어떨까? 아쉽지만 무리수는 컴퓨터가 정확히 표현할 수 없는 수이다. 왜냐하면 실수의 개수는 무한하지만 컴퓨터에서 수를 표현하는 비트 수는 유한하기 때문에 모든 실수를 정확하게 표현할 수 없다. 그렇기 때문에 대부분의 알고리즘은 유리수 입력으로 제한되며 이번 문제 역시 같은 제한 사항을 따른다.
1.2.2. Definition 2
라는 Flow network가 주어지고, 용량을 , 소스 노드를 , 싱크 노드를 라고 가정한다. 우리의 목표는 간선들의 집합()에서 음수가 아닌 실수 집합으로 가는 함수(간선의 유량)인 를 찾는 것이고 다음 조건을 만족할 때, 이 함수를 라고 부른다.
- (Capacity Condition) 각각의 간선 에 대한 함수값 는 용량 를 초과할 수 없다.
- (Flow Conservation) 소스 노드()와 싱크 노드()를 제외한 모든 내부 노드()는 들어오는 총 유량() 나가는 총 유량()이 같아야 한다.
1.2.3. Definition 3
위와 같이 정의된 의 값을 라고 표기하며 값은 다음과 같다.
우리의 목표는 가 최댓값을 가지는 를 찾는 것이고, 이러한 문제를 최대 유량 문제(Maximum flow problem)라고 부른다. 도입 부분에 다룬 문제 역시 최대 유량 문제를 찾는 것으로 볼 수 있다.
1.3. 표기법
알고리즘 설계에 앞서 몇 가지 표기법들을 선언하고 가자.
Flow 와 정점 가 주어졌을 때, 하에서 정점 로 들어오는 총 유량의 양을 라고 표기한다.
반대로 Flow 하에서 정점 에서 나가는 총 유량의 양을 라고 표기한다.
하나의 정점이 아닌 여러 개의 정점이 모인 집합에서도 위와 같은 식이 성립한다. 즉, 집합 에 대해서 다음과 같은 식이 성립한다.
f^{in}(S) := \sum_{e \text{ into } S}f(e) $$$$f^{out}(S) := \sum_{e \text{ out of } S}f(e)Figure 3에서 에 대해 , 이라 할 수 있다. 이때, 집합 내 유량 이동은 고려하지 않는다.
위 표기법과 Definition 2에 따라 인 모든 정점 에 대해 다음이 성립한다.
1.4. 문제 (Problem)
소스 노드가 이고 싱크 노드가 인 flow network가 주어졌을 때, 최댓값을 가지는 를 찾아라.
1.5. 예제
도입 부분의 예제를 다시 떠올려보자.
$\bigtriangleup$ Figure 1: A pipeline network
그리고 다음과 같은 최대 를 찾아냈다.
$\bigtriangleup$ Figure 2: Sending 30 units of oil
위 network flow는 유효한 로 볼 수 있다. 각 간선의 유량(flow)이 각각의 용량()을 초과하지 않으며(capacity conservation) 내부 노드인 와 에 대해 flow conservation이 성립하기 때문이다.
하지만 다음과 같이 모든 유량이 0인 역시 유효하다고 볼 수 있다. 모든 유량이 음수가 아닌 정수이며 capacity conservation과 flow conservation 역시 성립하기 때문이다.
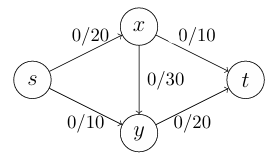
Figure 3: set up with all zero
Figure 3에서 의 값은 0이고 Figure 2에서 의 값은 30이다. 우리가 찾는 답은 Figure 2와 같이 최댓값을 가지는 를 찾는 것이다.
1.6. Greedy-like approach
우선 Figure 3과 같이 모든 유량이 0인 에서 시작해보자. 그리디 알고리즘적 접근에서 우리는 남아있는 용량에 대해 추가적인 유량을 보내며 최적의 값을 찾아볼 것이다. Figure 3에서는 모든 유량이 0이기 때문에 원래의 유량이 간선 위에 남아있다.
첫 번째로, "" 경로를 통해 최대 10의 유량을 보낼 수 있다. 이후 다음 그림과 같이 flow network를 업데이트 할 수 있다.
$\bigtriangleup$ Figure 4: After finding the path $s-x-t$ and pushing 10 units of flow
경로에서 10의 용량이 남아있으며 경로는 모든 최대 용량을 사용하였기 때문에 간선을 표시하지 않았다. 위의 방식과 같이 가능한 경로를 찾아 flow network 업데이트를 반복적을 할 수 있다. 두 번째 반복에서 "" 경로를 통해 최대 10의 유량을 보낼 수 있으며 세 번째 반복에서 "" 경로를 통해 최대 10의 유량을 보낼 수 있다. 세 번째 반복까지 하게 된다면 경로로 가는 간선이 다 사용되었기 때문에 그리디 알고리즘이 멈추게 되며 최종적인 답을 30으로 출력할 수 있다.
1.6.1. 반례
하지만 이 문제를 그리디 알고리즘으로 풀게 될 경우 반례가 발생하게 된다.
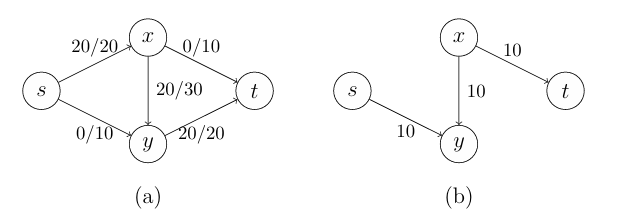
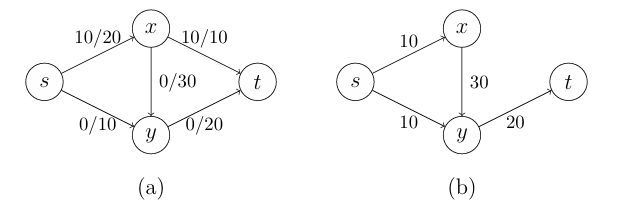
$\bigtriangleup$ Figure 5: A counterexample
만약 첫 번째 반복을 "" 경로를 통해 20의 유량을 보내게 된다면 Figure 5의 (b)와 같이 가능한 path가 없어지게 되고 알고리즘은 멈추게 된다. 그렇다면 이 그리디 알고리즘은 답을 20으로 출력하겠지만 우리는 이미 최적의 해답이 30이란 것을 알고 있다. 즉, 이번 문제에서 그리디 알고리즘으로 해답을 찾는 것은 적절하지 않다.
1.6.2. 아이디어
우리는 이미 노드에서 노드로 10의 유량이 보내져야 함을 알고 있다. 그렇다면 Figure 5에서 경로로 10의 유량을 보낸다고 가정하면 어떻게 될까? 그렇다면 노드의 flow conservation을 유지하기 위해 노드에서 노드로 가는 유량 10을 줄여야 한다. 그리고 노드의 flow conservation을 유지하기 위해 노드에서 노드로 10의 유량을 보내야 한다. 이를 통해 유효한 flow network를 만들 수 있으며 우리가 구하고자 하는 최적의 값 30 역시 얻을 수 있다. 즉, 그리디 알고리즘에서 얻은 flow network에서 초과 유량을 보내기 위해 기존 유량을 취소하여 최적의 값을 얻을 수 있다.
이러한 방식을 알고리즘으로 표현하기 위해 우리는 residual graph(잔여 그래프)를 정의할 수 있다.
1.7. Residual graph
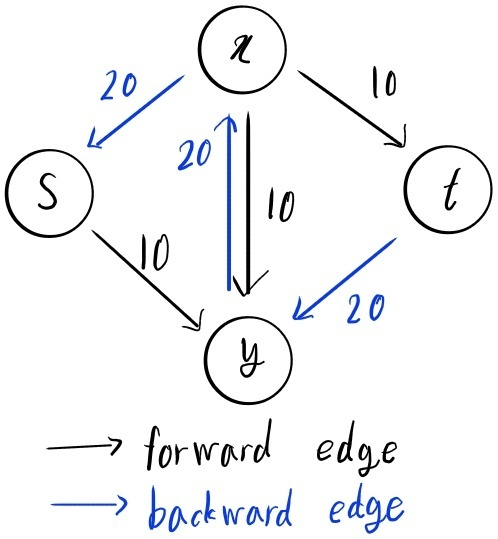
$\bigtriangleup$ Figure 6: Residual graph
앞서 설명했던 아이디어를 활용하여 Residual graph를 Figure 6와 같이 그릴 수 있다. 우선 그리디 알고리즘 실행 이후 남아있는 용량을 표시해 준다.(Forward edge) 여기서 초과 유량을 보내기 위해 기존 유량을 취소할 수 있으므로 기존 유량과 반대 방향인 간선을 도입한다.(backward edge) 이때, 취소된 유량의 최댓값은 해당 간선의 기존 유량 크기만큼만 가능하다. 예를 들어 노드에서 노드로 20의 유량이 있으므로 그와 반대 방향인 간선은 취소할 수 있는 최대 유량인 20이다. 이렇게 만들어진 residual graph는 남아있는 경로에 한해 유량을 보내는 것뿐만 아니라 유량의 취소 역시 고려한 잔여 용량 그래프이다.
다시 그리디 알고리즘의 반례 부분으로 돌아가 보자. Figure 5의 (b)에서 우리는 Figure 6과 같은 Residual graph를 그릴 수 있다. Residual graph에서 가능한 경로로 ""가 있으며 최대 10의 유량을 추가로 보낼 수 있다. 이때 경로의 경우 일종의 되돌리기(undoing)의 기능을 보여주고 있다. 따라서 알고리즘은 보낼 수 있는 최대 유량을 10 증가 시키게 되며 우리가 찾고자 하는 최적의 답을 도출하게 된다.
1.7.1. Definition 1
이제 Residual graph를 공식적으로 증명해보자.
간선 용량 를 가진 flow network 와 flow network 상의 유량 가 주어졌을 때, 유량 에 대한 의 residual graph(잔여 그래프)를 로 표기하며 다음과 같이 정의한다.
- Residual graph 의 노드 집합()는 원래의 flow network인 와 같다.
- 각각의 간선 에 대해 가 성립할 때, 는 의 용량을 가지는 간선 를 포함한다. (forward edge)
- 각각의 간선 에 대해 이 성립할 때, 는 의 용량을 가지는 간선 를 포함한다. (backward edge) Residual graph의 각 간선의 수는 그 간선을 사용하여 보낼 수 있는 최대 전달량이 되며 잔여 용량(Residual capacity)이라고 부른다.
edge 표현방식
방향성이 있는 그래프에서 간선을 표현할 때는 ”<>” 기호를 사용하여 방향성 간선을 표현하며 출발 노드를 앞에, 도착 노드를 뒤에 쓴다. ex) : 노드에서 출발하여 노드로 도착하는 간선
1.7.2. Definition 2
Residual graph에서 가능한 경로를 찾아 의 값을 증가시킬 수 있기 때문에 Residual graph의 경로를 augmenting path(증가 경로)라고 정의한다.
1.8. 알고리즘 (Subroutine)
Algorithm 1
1: function AUGMENT(f, P)
2: b ← minimum residual capacity of any edge on P
3: for each e = <u, v> ∈ P do
4: if e is a forward edge then
5: f(e) ← f(e) + b
6: else
7: e' := <v, u>
8: f(e') ← f(e') - b
9: return f
1.8.1. Lemma
1.8.1.1. Lemma 1
Flow network 의 유량 를 유효한 라 하고, 경로 를 Residual graph에서 단순한 path라고 할 때, 함수 는 flow network 의 를 반환한다.
1.8.1.1.1. 증명
를 함수 의 입력 유량, 을 함수의 출력 유량이라고 정의하자. 이때 우리는 이 유효한 라는 것, 즉 capacity condition과 flow conservation이 성립한다는 것을 보여주어야 한다.
이때, 알고리즘은 경로 상의 간선들에 대해서만 유량을 변경할 것이기 때문에 우리는 이 경로 내의 간선들에 대해서만 capacity condition을 확인하면 된다. 경로 내의 임의의 간선 에 대하여, 가 순방향 간선일 경우 다음과 같은 부등식이 성립한다.
f'(e) = f(e) + b \leq f(e) + (C_e - f(e)) = C_e $$$$f'(e) = f(e) + b \geq f(e) \geq 0반대로 가 역방향 간선일 경우 다음과 같은 부등식이 성립한다.
는 Residual graph에서 최소 잔여 용량(Residual capacity)으로 설정되기 때문에 위와 같은 부등식이 성립한다.
- 순방향:
- 역방향:
위를 통해 출력 유량 에 대해 capacity condition이 성립함을 알 수 있다. 이제 경로 내의 내부 노드들(, 제외)에 대해 flow conservation이 성립하는지 확인해보자.
경로 를 단순한 경로로 설정했기 때문에, 경로 중 순환하는 부분이 나타나지 않는다. 우리는 를 최소 잔여 용량(Residual capacity)으로 설정하였지만, 경로 가 단순한 경로가 아닌 순환 경로가 존재한다면 최대 용량을 초과하거나 유량을 음수로 만드는 상황이 발생하게 된다. 이 때문에 를 단순한 경로로 설정하고 flow conservation 증명에 있어 중요한 가정 부분이다.
경로 는 단순한 경로이기 경로 내의 내부 노드()의 들어오는 간선과 나가는 간선은 각각 하나씩만 존재한다. 각각의 간선을 , 라고 설정하자.
우선 두 간선 모두 순방향 간선으로 가정하자. 그러면 다음과 식이 성립한다.
직관적으로 순방향 간선이기 때문에 노드 를 기준으로 들어오는 간선과 나오는 간선의 유량에 모두 가 추가되기 때문에 의 유량 변화량은 이 되어 flow conservation이 성립한다. 위의 공식으로 본다면 경로 외부에서 들어오거나 나가는 간선들의 유량은 바뀌지 않으므로 경로 내부의 유량 변화만 고려하면 된다. 기존에 노드 로 들어오는 양에서 기존의 에서 들어오는 양을 빼고 대신 새롭게 들어오는 양을 더하게 되면 노드 로 들어오는 최신 유량이 된다. 노드 로 나가는 최신 유량 역시 비슷한 방식으로 계산할 수 있다. 그리고 순방향에서 각각의 변화량은 가 되며 기존 flow는 유효한 이므로 의 값은 0이 되며 의 값도 0이 되어 최종적인 값이 0이 된다. 이를 통해 노드 가 가지는 두 간선이 모두 순방향일 경우 flow conservation이 성립함을 알 수 있다.
다음으로 는 순방향 간선, 는 역방향 간선이라고 가정하자. Residual graph에서 가 역방향 간선이므로 원래의 flow network에는 간선이 존재하며 유량이 감소하는 방향으로 변하게 된다. 즉, 함수 AUGMENT를 거치면서 노드 가 가지는 간선들 중 유량이 변하는 간선은 , 두 개가 존재한다. 따라서 다음과 같은 식이 성립한다.
우리가 두 간선이 순방향일 때를 가정했을 때와 같이 둘 중 하나가 역방향일 경우도 같은 방식으로 식을 조작하여 위의 식을 유도할 수 있다. 이때는 원래의 network flow에서 노드 로 들어오는 간선의 유량만 변하므로 부분만 변형하면 된다. 기존 flow는 유효한 이므로 이 성립하며 따라서 는 순방향, 는 역방향 간선일 경우 flow conservation이 성립함을 알 수 있다.
이제 남은 경우로 는 역방향, 가 순방향 간선일 경우와 두 간선 모두 역방향 간선일 경우 flow conservation이 성립함을 보여야 한다. 이 남은 두 경우는 앞서 살펴보았던 증명 방법을 통해 flow conservation이 성립함을 알 수 있다. 따라서 경로 내의 모든 내부 노드들에 대해 flow conservation이 성립함을 알 수 있고 Lemma 1은 참이 된다.
1.9. 알고리즘 (Ford-Fulkerson algorithm)
1.9.1. 알고리즘 정확성 분석
우리가 알고리즘의 정확성을 판단할 때 고려해야 할 두 가지 사항이 있다. 첫 번째는 알고리즘이 종료되는지, 그리고 알고리즘이 종료할 때 올바른 답을 생성하는 지 보여주어야 한다.
1.9.1.1. Lemma 1
모든 간선의 유량과 잔여 용량은 Ford-Fulkerson 알고리즘의 어떠한 실행에서도 정수(integer)로 유지된다.
1.9.1.1.1. 증명
Lemma 1은 반복 횟수의 귀납법에 의해 증명할 수 있다.
우리는 문제의 Definition에서 모든 간선의 용량은 음이 아닌 정수로 가정하였다. Ford-Fulkerson 알고리즘이 실행되기 전, 즉 0번 반복되었을 경우, 현재의 유량 는 0이 되며 Residual graph의 모든 용량은 초기 용량, 즉 정수가 된다. (Base step)
그리고 k번째 반복의 시작 지점에 현재 유량과 Residual graph의 잔여 용량이 모두 정수라면(Inductive hypothesis), Ford-Fulkerson 알고리즘이 찾아낸 단순한 경로 의 모든 용량은 정수가 될 것이다. 이후 AUGMENT(, )는 이 정수들 중 가장 작은 정수를 선택하고 남은 간선들에는 이 정수를 빼고 더하게 되며, 이때 용량들은 정수로 유지된다. 따라서 k번째 반복 종료 지점에서도 변화된 유량 및 잔여 용량들도 항상 정수로 유지된다. (Inductive step)
1.9.1.2. Lemma 2
Ford-Fulkerson 알고리즘의 각 반복 후에는 명백하게 유량의 값, 를 증가시킨다.
1.9.1.2.1. 증명
Residual graph 구성 방식에 따라, Residual graph 내의 모든 잔여 용량은 양수이다. 따라서 AUGMENT(, ) 함수는 항상 경로 상에서 양수인 최소 잔여 용량 를 가진다. 경로 상의 첫 번째 간선은 소스 노드 로부터 나가는 간선이 될 것이고, 이 간선은 순방향 간선이어야 한다. 만약 첫 번째 간선이 역방향 간선일 경우, 원래의 flow network에서는 소스 노드 로 들어가는 간선이 있다는 것이고, 이는 우리의 문제 정의 및 가정에 위배된다. 따라서 경로 상의 첫 번째 간선은 소스 노드 로부터 나가는 순방향 간선이다. 그리고 경로 를 단순한 경로라 가정하였기 때문에 소스 노드 를 떠난 후에는 다시 돌아오지 않는다. 즉, 소스 노드 로 유입되는 양이 발생하지 않는다. 유량의 값 이며 소스 노드 가 가지는 간선들 중 경로 상의 순방향 간선의 유량만 만큼 증가하게 되므로 가 만큼 증가하게 되어 최종적으로 유량의 값 가 각 반복마다 증가하게 된다.
Lemma 1과 Lemma 2를 통해 직관적으로 Fold-Fulkerson 알고리즘이 끝난다는 것을 알 수 있다. 최대 유량값 는 유한한 값을 가질 것이고, Lemma 2에서 알고리즘의 각 반복마다 의 값은 커지기 때문에 특정 지점에서는 알고리즘이 종료될 것이다. 이를 엄밀히 주장하기 위해 다음과 같이 유량값의 상한선을 설정한다.
1.9.1.3. Lemma 3
로 설정할 때, Ford-Fulkerson 알고리즘은 최대 번의 반복 내에 종료한다.
1.9.1.3.1. 증명
Flow network 의 임의의 에 대해 다음의 식이 성립한다.
유량값은 소스 노드에서 나가는 유량의 합이 되며 이 값은 각각의 간선이 가지는 최대 용량의 합 보다 작거나 같다. 따라서 는 소스 노드에서 나가는 간선들의 최대 용량을 초과할 수 없다. 앞서 설명했던 Lemma 1과 Lemma 2를 통해 Ford-Fulkerson 알고리즘은 유량값 를 최소 1만큼 증가시키며 알고리즘 초기 상태에서 모든 간선의 유량은 0으로 초기화되기 때문에 while loop은 최대 번 만큼 실행될 수 있다. 이를 통해 Lemma 3과 성립함을 알 수 있다.
지금까지 알고리즘이 유한시간 내 종료된다는 것을 알게 되었다. 이제 알고리즘의 정확성을 증명하기 위해 알고리즘이 정확한 정답을 도출하는지, 즉 최대 유량을 반환하는지를 확인해야 한다. 이를 인증 알고리즘(certifying algorithm)을 통해 증명한다. 우리가 앞선 구간 스케줄링 알고리즘을 증명할 때 사용했던 것처럼 인증 알고리즘은 최종 결과뿐만 아니라 인증서의 역할을 하는 추가적인 정보(side information) 역시 생성하여 이러한 정보를 바탕으로 알고리즘의 출력 값보다 더 최적의 값은 없다라는 것을 통해 증명하는 방식이다.
첫 번째로 인증서(certificate)를 정의함으로써 시작한다.
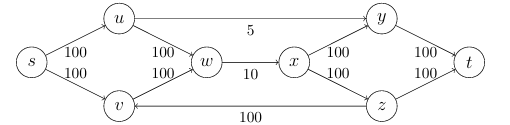
Figure 7: A flow network with the maximum flow value of 15
위 그림은 최대 유량이 15인 flow network의 그림이다. 만약 최대 유량을 모른다고 가정할 때, 어떻게 최대 유량의 상한선을 결정할 수 있을까? 여기서 소스 노드를 포함하는 노드 집합 와 싱크 노드를 포함하는 노드 집합 로 묶는다면, 소스 노드에서 싱크 노드로 가기 위해 이 둘 사이의 간선을 통과해야 하며, 싱크 노드로 가는 간선들의 용량 합인 15를 최대 유량의 상한선으로 설정할 수 있다. 이를 통해 알고리즘이 출력한 값보다 큰 최대 유량값이 존재할 수 없음을 보여줄 수 있다.
이를 공식화하기 위해 먼저 소스 노드를 포함하는 집합과 싱크 노드를 포함하는 집합에 대해 다음과 같이 정의한다.
1.9.1.4. Definition 1
Flow network 에서 소스 노드 를 포함하는 집합 와 싱크 노드 를 포함하는 집합 가 존재하며 , 가 성립할 때, 를 flow network 의 cut이라 정의한다.
즉, flow network에 존재하는 모든 노드들은 소스 노드를 포함하는 묶음과 싱크 노드를 포함하는 묶음 둘 중 하나에 반드시 속해야 하며 두 묶음은 겹치면 안 된다는 것을 의미한다.
이렇게 정의한 cut을 통해 최대 유량의 상한선을 설정해야 하므로 다음과 같은 정의를 추가한다.
cut
위의 정의에서 cut 부분 집합을 설정할 때, 소스 노드 혹은 싱크 노드와 연속적으로 연결되어 있는 부분집합을 설정할 필요는 없다. 예를 들어 Figure 7에서, , 로 설정하였을 때, 집합 에서 싱크 노드 와 내부 노드 는 떨어져 있는 관계이지만 위의 Definition에 위배되지 않기 때문에 해당 부분집합 역시 cut에 속한다.
1.9.1.5. Definition 2
집합 에서 나가는 모든 간선들의 용량의 합()을 cut 의 용량이라 정의하고 로 표기한다.
이렇게 정의한 cut과 최대 유량과의 관계를 정의하기 위해 다음의 보조 정리를 주장할 수 있다.
1.9.1.6. Lemma 4
의 임의의 유량 와 임의의 cut 에 대해 다음의 식이 성립한다.
1.9.1.6.1. 증명
다음의 식을 생각해보자.
집합 에 속한 모든 정점 에 대해 를 구한 후 이를 모두 합해보자. 만약 집합 안의 정점에서 집합 안의 정점으로 가는 간선이 있을 때, 이 두 정점을 , 라고 가정해보자. 그러면 두 정점 모두 집합 안의 노드이며 에서 로 가는 간선이 있다고 하면 기준으로 의 값이 해당 간선 용량 만큼 커지며 기준으로 의 값이 해당 간선 용량 만큼 커진다. 이를 모두 합할 때, 결국 서로 다른 부호로 상쇄되므로 정점 내 간선의 용량은 상쇄되어 없어질 것이다. 또한, 밖의 노드에 대해서 간선의 들어오는 용량과 나가는 용량은 고려하지 않는다. 이를 종합하면 밖의 노드는 고려하지 않기 때문에 밖으로 나가는 용량인 과 안으로 들어오는 용량인 은 집합 내의 정점에 대해 한 번씩만 계산되며, 정점 내의 간선은 상쇄되므로 결국 위의 식은 Lemma 4에서 주장한 식인 와 동일하다.
또한, flow conservation에 따라 소스 노드 를 제외한 집합 에 속하는 모든 내부 노드들에 대해서는 flow conservation이 성립하며 이를 통해 다음과 같은 식이 성립한다.
여기서 소스 노드 로 들어오는 간선은 없다고 가정하였으므로 이다. 따라서 다음의 식이 성립한다.
따라서 Lemma 4가 성립함을 알 수 있다.
Lemma 4를 통해 우리는 임의의 유량 의 양은 cut의 순유량값과 같은 것을 알 수 있으며 이를 통해 각각의 집합 를 가로지르는 간선의 순유량값과 같은 것을 알 수 있다. Lemma 4를 통해 최대 유량값의 상한선을 설정할 수 있다.
1.9.1.7. Corollary 1
임의의 와 임의의 cut 에 대해 다음의 부등식이 성립한다.
1.9.1.7.1. 증명
Lemma 4와 cut의 용량에 대한 정의를 통해 증명할 수 있다.
이를 통해 만약 알고리즘이 유량이 100인 를 출력하고, 용량이 100인 cut이 있다는 것도 증명할 수 있다면, 알고리즘이 최대 유량값을 가지는 를 출력한다는 것을 증명(certificate)할 수 있다.
1.9.1.8. Lemma 5
경로를 가지지 않는 Residual graph 를 만족하는 가 있다면, 인 cut인 가 항상 존재한다.
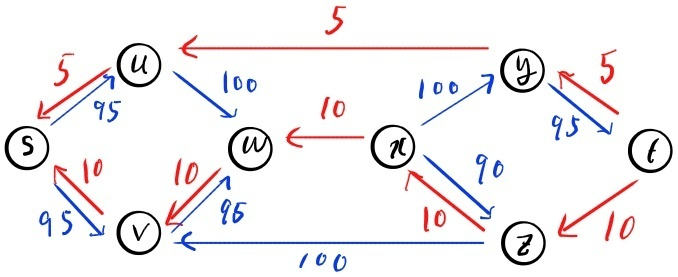
Figure 8: Residual graph of the flow network of Figure 7
1.9.1.8.1. 증명
소스 노드 로부터 도달할 수 있는 정점들의 집합을 라 하고 나머지 정점들의 집합을 라고 하자. 이때 집합 에는 소스 노드 가 반드시 포함되는데, 소스 노드는 그 자체로 소스 노드에 도달할 수 있는 정점이기 때문이다. 그리고 Lemma 5에서 경로를 가지지 않는 Residual graph 를 가정하였으므로 싱크 노드 는 소스 노드 로부터 도달할 수 없으므로 집합 에 속한다. 집합 와 집합 를 설정하는 정의로부터 집합 는 집합 의 여집합으로 설정되어 있으며 집합 는 소스 노드 를, 집합 는 싱크 노드 를 포함하고 있으므로 Definition 1에 따라 cut이 성립한다.
이제 집합 에서 집합 로 가는 임의의 간선 를 가정해보자. 이때, 정점 는 집합 에 속하고 정점 는 집합 에 속해야 한다. 앞서 우리는 집합 에 속한 정점들은 Residual graph 에서 소스 노드 로부터 도달할 수 없는 점들이므로 간선 는 Residual graph 에는 존재하지 않음을 알 수 있다. 그리고 이는 간선 의 용량을 모두 유량에 사용했다는 의미이기도 하다(). 이에 더해 우리는 간선 를 집합 에서 집합 로 가는 임의의 간선으로 지정하였으므로 집합 에서 집합 로 가는 모든 간선 에 대해 가 성립함을 알 수 있다. 이에 따라 집합 에서 나가는 총 유량, 은 집합 에서 나가는 총 용량과 같음을 알 수 있으며 이는 Definition 2에 따라 와 같다. 따라서 가 성립한다.
이제 집합 에서 집합 로 가는 임의의 간선 를 가정해보자. 이는 집합 로 들어오는 임의의 간선이며, 정점 는 집합 에, 정점 는 집합 에 속한다는 것을 의미한다. 그리고 Residual graph 에서는 간선 가 존재하지 않는다는 것을 우리의 증명 가정으로부터 알 수 있다. 이는 간선 의 반대 방향 간선이 존재하지 않는다는 것을 의미하며 Residual graph 정의에 따라 간선을 사용하지 않음을 알 수 있다. 즉, 임의의 간선 에 대해 이 성립함을 알 수 있으며, 이는 을 의미한다.
Lemma 4와 위에서 알게된 내용을 토대로 다음과 같은 식이 성립한다.
따라서 Lemma 5가 성립함을 알 수 있다.
위의 Lemma들과 Corollary를 바탕으로 다음과 같은 Corollary 2를 작성할 수 있다.
1.9.1.9. Corollary 2
Ford-Fulkerson 알고리즘은 최대 유량을 반환한다.
1.9.1.9.1. 증명
를 Ford-Fulkerson 알고리즘에 의해 반환된 유량의 값이라고 가정하자. 알고리즘이 종료된 후 나온 Residual graph 는 경로를 가지고 있지 않으며 Lemma 5에 따라 와 같아지는 용량을 가진 cut 가 존재하며 corollarly 1에 따라 의 값은 임의의 cut 의 용량보다 작거나 같아야 함을 알 수 있다. 이에 따라 의 값은 최대 유량값임을 알 수 있다.
우리가 이전 구간 스케줄링 문제에 대해서도 이와 같이 certification algorithm 증명을 하였지만 이번 cut을 이용한 certification 증명은 이보다 더욱 엄밀한(tight) 증명이다. 실제로 구간 스케줄링 문제의 경우 우리가 최대값에 대한 경계를 지정하였지만 이러한 경계가 강하지 않아 실제 최적해와 동떨어진 값일 수 있다. 하지만 cut의 경우, 만약 최대 유량 값이 100이라면 용량이 100인 cut이 항상 존재하며 알고리즘이 최적의 값을 반환환함을 보여줄 수 있다. 이를 다음과 같이 정리할 수 있다.
1.9.1.10. Theorem 1
(the max-flow min-cut theorem) 모든 flow network에서 flow의 최대 유량값은 cut의 최소 용량과 같다.
1.9.1.11. Theorem 2
만약 flow network의 모든 용량이 정수라면, 모든 간선의 유량이 정수인 최대 유량이 존재한다.
1.9.1.11.1. 증명
Theorem 2는 알고리즘적 증명으로 성립함을 알 수 있다.
우리가 알고리즘의 정확성을 분석하는 과정에서 Ford-Fulkerson 알고리즘은 매 반복마다 정수 형태의 유량과 잔여 용량을 가지고 있음을 증명했다. 따라서 알고리즘이 종료된 후 최대 유량을 반환할 것이며 최대 유량과 이를 만드는 간선들의 유량은 모두 정수 형태라는 것을 알 수 있다.
이에 더해 Theorem 2의 경우 역은 성립하지 않는다. 모든 간선의 유량이 정수인 최대 유량이 존재한다고 하더라도, 최대 유량이 거치지 않는 간선의 용량은 정수가 아닌 값이 될 수 있기 때문이다.
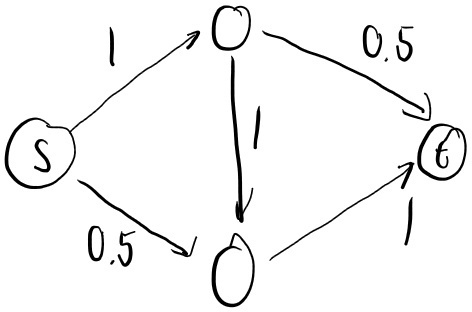
Figure 9: Couter example of the converse of theorem 2
하지만 모든 용량이 정수라면 Ford-Fulkerson 알고리즘은 항상 모든 유량이 정수인 최대 유량을 반환하기 때문에 Theorem 2가 성립함을 알 수 있다.
1.9.2. 알고리즘 실행 시간 분석
지금까지 우리는 알고리즘의 정확성을 판단하였으며 유한 시간 내에 종료한다는 것을 알게 되었다. 이를 바탕으로 Ford-Fulkerson 알고리즘의 실행 시간을 분석해 보자.
을 노드의 수, 을 flow network의 간선 수라고 정의하자.
1.9.2.1. Theorem 1
Ford-Fulkerson 알고리즘은 의 시간복잡도를 가진다.
1.9.2.1.1. 증명
는 유량 에 대한 의 Residual graph이며 우리가 실제로 구성해야 하는 그래프이다. 입력으로 주어지는 노드와 간선을 통해 우리의 flow network 를 알 수 있으며 현재의 유량 역시 무엇인지 알기 때문에(초기 상태 0으로 시작하여 매 반복마다 업데이트된 유량 를 받음) 이를 통해 Residual graph 를 알 수 있다. 매 반복마다 를 업데이트 한다고 가정하면, 매번 노드의 수 과 간선의 수 을 체크해야 하므로 구성 시 의 시간이 걸리게 된다.
구성 방법
를 구성하는 방식은 다양할 수 있다. Residual graph를 유지하는 경우, 혹은 바꾼 경로에 한해서 Residual graph를 수정하는 경우 등으로 제한하여 구성한다면 시간복잡도를 줄일 수 있을 것이다. 하지만 이번 강의에서는 가장 naive한 방식으로 매 반복마다 를 새롭게 구성하는 방식을 택하여 간단히 시간복잡도를 계산해보고자 한다. 그래프를 인접 리스트로 표현한다고 가정하면 인접 리스트의 크기는 노드의 개수인 이 되며 인접 리스트 내의 각 원소(노드)가 각각의 간선들의 리스트를 가리키게 된다. 이러한 리스트들을 전부 모으면 개의 간선들이 된다. 각 간선에 대해 상수 시간을 소요하며, 배열의 각 항목(노드)에 대해서도 상수 시간을 소요하게 되므로 전체 시간복잡도는 이 된다.
다음으로 BFS나 DFS를 통해 단순한 경로를 찾을 수 있으며 이때의 시간복잡도 역시 이 된다.
Residual graph에서 간선의 수
BFS나 DFS 수행은 원래의 flow network가 아닌 Residual graph에서 수행되며 Residual graph의 경우 노드의 수는 같지만 현재 유량에 따라 간선의 수는 달라질 수 있다. 하지만 Residual graph가 가질 수 있는 최대 간선의 수는 이기 때문에 시간복잡도 이 성립한다고 할 수 있다.
초기화 단계, 즉 현재 유량을 0으로 설정하는 단계는 원래의 flow network 그래프의 간선 집합을 그대로 들고 온 후, 각각의 용량에 0을 부여하는 방식을 통해 의 시간복잡도로 실행할 수 있다.
따라서 전체 실행 시간은 초기화 단계에서 의 시간을 소요, 각 반복마다 의 시간을 소요하며 반복 횟수는 최대 이므로 전체 알고리즘의 시간복잡도는 가 된다. 이때 우리는 문제 정의 부분에서 모든 노드가 적어도 하나의 인접 노드를 있다고 가정했으며 그렇기 때문에 각 노드에 대해 무방향성 간선의 개수를 센 후 이를 모두 더하면 간선 수의 두 배가 된다(). 그 이유는 각 간선은 양 끝에 두 개의 노드를 가지고 있기 때문에 각 노드별로 하나의 간선을 두 번 계산하기 때문이다. 또한, 각 노드가 하나 이상의 인접 간선을 가지므로 각 노드의 무방향성 간선의 개수를 모두 더한 값은 적어도 이상이어야 한다(). 이를 바탕으로 , 즉, 이 된다. 따라서 의 값은 에 의해 지배될 수 있으므로 시간복잡도 를 가진다고 정할 수 있다.
시간복잡도 계산
이 성립하기 때문에 은 다음의 상한선이 성립한다. 의 크기가 을 넘지 않으므로 은 의 상한선을 가진다고 볼 수 있어 이와 같이 단순화시킬 수 있다.
1.10. 효율적인 알고리즘
이때까지 Ford-Fulkerson 알고리즘의 시간복잡도를 계산해보았다. 언뜻 보기에 시간복잡도 는 다항식으로 표현된 것 같지만, 실제로 입력(비트 수)에 대해 기하급수적(exponentially)으로 커지게 되며 이는 알고리즘이 효율적이라고 말할 수 없다. ‘효율적인’ 알고리즘에 대해 다음과 같이 정의할 수 있다.
1.10.1. Definition 1
알고리즘의 실행 시간이 입력 항목의 수에 대해 다항식으로 표현될 때, 해당 알고리즘은 강한 다항식(strongly polynomian)이라 정의한다.
1.10.2. Definition 2
알고리즘의 실행 시간이 입력을 표현하는 총 비트 수에 대해 다항식으로 표현될 때, 해당 알고리즘은 약한 다항식(weakly polynomial)이라 정의한다.
약한 다항식 알고리즘(효율적인 알고리즘) vs 강한 다항식 알고리즘
앞서 살펴본 예제 중 최장 비감소 부분 수열 문제를 떠올려 보자. 개의 정수가 주어지고 그 중 가장 큰 정수를 이라 가정했을 때, 전체 배열의 비트 수는 이라 할 수 있다. 그리고 이 문제를 해결하는 알고리즘의 실행 시간은 이었으며 이는 상한선도 성립함을 의미한다. 따라서 이 알고리즘의 경우 입력을 표현하는 데 사용되는 총 비트 수에 대해 다항식으로 표현할 수 있으므로 약한 다항식 알고리즘(효율적인 알고리즘)에 해당한다. 하지만 이 알고리즘은 입력 비트 수를 고려하지 않고 입력 항목 수에 대한 다항식으로 표현할 수 있기 때문에 강한 다항식 알고리즘이라고도 부를 수 있다. 즉, 각각의 입력의 크기에 관계없이 입력 항목 수만으로 알고리즘의 시간복잡도가 다항식으로 결정되었기 때문에 강한 다항식 알고리즘이라 한다. 지금까지 본 대부분의 알고리즘(dp, greedy 등)은 입력 항목 수에 대해 다항식으로 표현할 수 있으므로 강한 다항식 알고리즘이라 부를 수 있다. CPU의 RAM 모델은 64비트 이내의 입력값은 상수 시간 내에 실행할 수 있기 때문에 비트 수를 초과하지 않는 입력값을 가진다면 입력값의 비트 수는 시간복잡도 계산에 영향을 주지 않는다. 만약 어떤 알고리즘이 강한 다항식 알고리즘이라면 그 알고리즘은 약한 다항식 알고리즘에 속하기도 한다. 각각의 입력을 나타내는 비트 수가 적어도 1 이상이기 때문에 입력 항목 수에 대해 다항식으로 상한선이 제한된다면 입력을 나타내는 총 비트 수에 대한 다항식으로도 상한선이 제한될 수 있기 때문이다. 위의 최장 비감소 부분 수열 문제와 같이 이 성립하므로 역시 성립하는 것을 통해 알 수 있다.
1.10.3. Definition 3
알고리즘의 실행 시간이 입력 항목의 수와 입력의 크기(magnitude)에 대한 다항식으로 표현될 때, 해당 알고리즘은 유사 다항식(pseudo-polynomial)이라 정의한다.
유사 다항식(pseudo-polynomial)
우리가 정수 곱셈 알고리즘을 떠올려 볼 때, 가장 순진한(naive) 방식으로 구현한 알고리즘이 바로 유사 다항식 알고리즘이다. 정수 가 주어졌을 때, 시간 복잡도가 두 정수의 곱, 즉 입력의 비트 수가 아닌 입력 크기 자체의 곱으로 구현되었기 때문이다. 이와 유사하게, 앞서 구현한 Ford-Fulkerson 알고리즘 역시 유사 다항식 알고리즘이다. 간선의 수 은 입력 항목의 개수가 되고, 용량들의 합 는 각각의 간선이 가지는 크기의 합이므로 유사 다항식의 형태로 표현된 것을 알 수 있다. 따라서 해당 알고리즘 역시 유사 다항식 알고리즘이다.
우리는 약한 다항식 알고리즘이 성립할 경우 해당 알고리즘을 효율적이라 할 수 있기 때문에 우리의 목표는 약한 다항식 알고리즘 혹은 강한 다항식 알고리즘을 구현하는 것이다. 그리고 Ford-Fulkerson 알고리즘은 유사 다항식 알고리즘이기 때문에 효율적인 알고리즘이라고 할 수 없다.
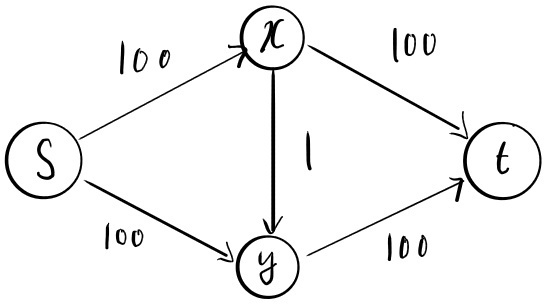
Figure 10: A bad instance for the Ford-Fulkerson algorithm
위의 flow network가 주어졌다고 가정해보자. 그렇다면 이 flow network의 최대 유량은 200이라는 것을 쉽게 알아볼 수 있다. 경로로 100, 경로로 100의 유량을 보내 총 200의 유량을 보낼 수 있기 때문이다. 하지만 Ford-Fulkerson algorithm은 최악의 경우 다음과 같이 시행될 수 있다.
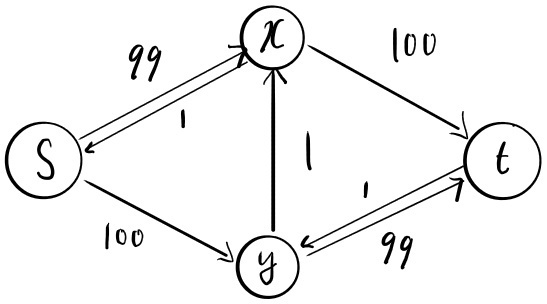
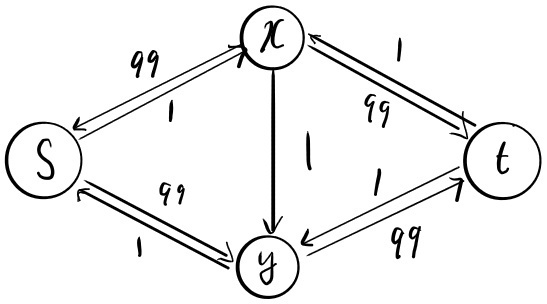
Figure 11: residual graph of 2nd and 3rd iteration of the Ford-Fulkerson algorithm
위 그림과 같이 2번째 반복에서 알고리즘이 경로를 선택하면 유량은 1이 될 것이고 그림과 같이 가 1의 용량을 가진 역방향 간선이 있는 residual graph가 생성된다. 그리고 3번째 반복에서 경로를 선택하면 유량 1을 선택하고 가 1의 용량을 가진 순방향 간선이 있는 residual graph가 생성된다. 이 과정을 200번 반복하면 알고리즘이 종료되어 최대 유량 200을 반복한다. 하지만 이 알고리즘은 효율적인 알고리즘이 아니다. 이는 Ford-Fulkerson 알고리즘의 불완전한 증명에서 비롯된다. Ford-Fulkerson 알고리즘을 시행할 때 우리는 그저 ‘매 실행마다 정수의 유량과 잔여 용량을 가지는 Residual graph를 생성’하는 선택이라고 명시했기 때문이다. 이 때문에 알고리즘은 가능한 모든 경로 중 최악의 경로를 선택할 수 있으며 결국 최악의 실행 시간을 가지게 된다. 만약 위 그림에서 알고리즘이 다음과 같이 선택했다면 실행 시간을 어떻게 될까?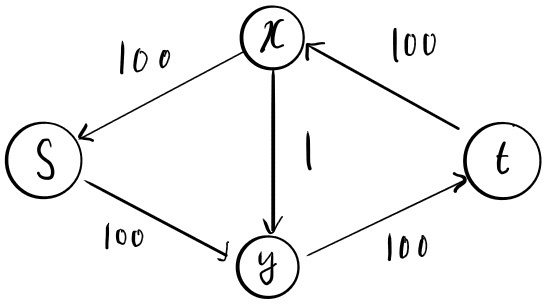
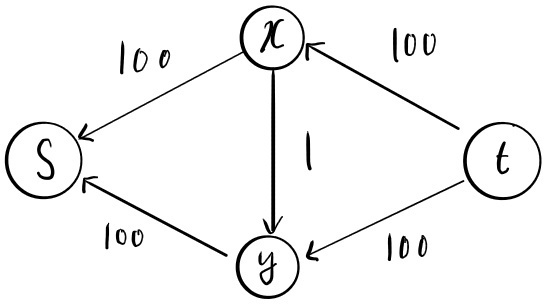
$\bigtriangleup$ Figure 12: residual graph of the efficient Ford-Fulkerson algorithm
위 그림과 같이 첫 실행에서 경로를 선택하면 100의 유량을 얻을 수 있으며 이후 경로를 선택하면 100의 유량을 얻게 되며 더 이상 경로를 가지지 않으므로 최대 유량 200을 반환하게 된다. 위의 비효율적 알고리즘과 달리 이와 같은 방식으로는 단 2번 만에 답을 도출하게 된다. 즉, 올바른 증가 경로(augmenting path)를 선택한다면 Ford-Fulkerson 알고리즘을 더 효율적으로 바꿀 수 있다.
1.10.4. 아이디어
우리가 작성한 알고리즘에서 augmenting path가 가장 작은 병목 용량을 가진 경로를 통해 유량을 증가시키기 때문에 Ford-Fulkerson 알고리즘이 작은 용량을 가진 간선(위 그림의 예에서는 1)을 선택해도 정상적으로 작동이 되지만 최악의 실행 시간을 가지게 된다. 그렇다면 augmenting path에 들어가기 전, 아주 작은 용량을 가진 간선을 제외하고 비교적 큰 용량을 가진 간선들부터 살펴본다면 어떨까? 만약 그 중 경로가 있다면 우리는 그 간선들을 먼저 선택한 후, 후에 남겨둔 작은 용량들을 통해 가능한 경로를 찾아보는 것이다. 그렇다면 위와 같이 아주 작은 용량을 가진 간선을 선택하여 최악의 실행 시간을 가지는 경우를 제거할 수 있을 것이다.
1.11. 알고리즘 수정
1.11.1. Definition 1
Residual graph 에서 임계값 보다 크거나 같은 잔여 용량을 가진 간선들로만 구성된 subgraph를 라고 표기한다.
우선 값을 큰 수로 설정하여 Residual graph 전체가 아닌 부분 그래프 에서 가능한 경로를 먼저 찾은 후 이전 알고리즘과 같이 시행한다. 이후, 경로가 존재하지 않을 때, 값을 줄인 후, 또다시 가능한 경로를 찾는 것을 반복하며 알고리즘을 수행한다.
1.11.2. 수정된 알고리즘 분석
우선 이전의 Ford-Fulkerson 알고리즘과 같이 모든 유량을 0으로 초기화한다. 이후 수정된 버전에서는 임계값 를 지정해야 하므로 우리는 이를 소스 노드에서 나가는 간선들 중 용량이 가장 큰 값을 선택한 후, 이보다 작은 2의 거듭제곱 중 가장 큰 값을 선택한다. 우리가 살펴볼 그래프는 임계값 보다 큰 용량을 가진 간선들만을 살펴볼 것이기 때문에 소스 노드에서 나가는 간선들 중 적어도 하나는 선택될 수 있도록 하기 위해 이와 같이 값을 초기 설정한다. 이렇게 고른 값을 바탕으로 만약 그래프에서 경로가 있다면 그 중 단순한 경로를 찾은 후 알고리즘으로 용량과 Residual graph를 업데이트 시켜준다. 만약 경로를 가지는 가 없다면 우리는 값을 2로 나누어 업데이트를 한다. 이것이 우리가 초기 설정에서 값을 2의 거듭제곱으로 설정한 이유이다. 이렇게 반복이 되다 보면 값이 1이 되는 순간이 올 것이고, 이는 기존의 Residual graph를 보는 것과 같다. 기존 Residual graph에 경로가 존재하지 않는다면 while loop이 종료되고 알고리즘은 최종 유량 를 출력한다.
위 알고리즘은 증명할 필요없이 정확성을 지닌다는 것을 알 수 있다. 우리는 이전의 Ford-Fulkerson 알고리즘에서 정확성을 증명하였으며 이는 알고리즘이 여러 개의 가능한 경로 중 어떠한 것을 선택하여도 항상 정답을 출력한다는 것을 증명했다. 위의 수정된 알고리즘은 가능한 경로 선택에 이상의 용량을 가진 특정 경로를 선택하는 것이다. 따라서 넓은 범위로 시행되는 알고리즘이 성립한다는 것을 알기 때문에 특정 범위로 시행되는 알고리즘 역시 성립함을 알 수 있다.
그러면 수정된 알고리즘의 실행 시간을 분석해보자.
1.11.3. Lemma 1
수정된 알고리즘의 Augmentation 실행 횟수는 최대 이다.
1.11.3.1. 직관적 추론
알고리즘은 3번째 줄의 while loop을 만큼 반복한다는 것을 알 수 있으며 내부 while loop은 이만큼 시행되기 때문에 최대 번 반복됨을 알 수 있다. 따라서 Augmentation의 실행 횟수는 최대 이다.
왜 가 아닌 일까?
의 값을 로 가정해보자. 그러면 값은 으로 총 번 반복하게 된다. 따라서 반복 실행 횟수의 상한선을 정할 때 로 설정한다. 위 내용에 따라 내부 while loop의 실행 횟수는 이라는 것을 알 수 있다. 이 값은 항상 보다 작거나 같기 때문에 최대 실행 횟수의 상한선을 정할 때 ceiling을 사용하는 이유이다.
1.11.4. Theorem 1
수정된 알고리즘의 실행 시간은 이다.
1.11.4.1. 증명
앞선 Lemma 1에서 Augmentation의 실행 횟수가 라는 것을 알 수 있다. 그리고 Augmentation 과정 내에서도 경로 P를 따라 유량을 수정한다. 이때, 경로 P의 길이는 최대 이며 이므로 Augmentation 과정 내에서 이라는 실행 시간이 발생한다. 따라서 전체 알고리즘의 실행 시간은 이다.
Augment 실패 시 발생하는 시간
에서 가능한 경로가 발생하지 않는 경우라도 이를 확인하기 위해 DFS/BFS 방식으로 경로 탐색을 하며 의 시간이 발생한다. 이는 각 단계가 끝나기 전에 항상 발생하며 전체 단계 수가 이므로 시간이 걸린다. 하지만 전체 알고리즘 실행 시간이 이므로 알고리즘 전체 시간 복잡도에 영향을 미치지 않는다.
위의 용량 스케일링(capacity scailing)을 사용한 수정된 Ford-Fulkerson 알고리즘은 약한 다항식 알고리즘, 즉 효율적인 알고리즘이라 할 수 있다. 용량 를 나타내기 위해 입력 값은 최소 개의 비트가 사용되기 때문이다. 또한 각 간선을 표현하기 위한 비트가 적어도 하나 이상 필요하기 때문에 역시 전체 입력 비트 수보다 작거나 같음을 알 수 있다. 따라서 위의 수정된 알고리즘은 입력 비트 수에 대해 다항식으로 표현되는 시간복잡도를 가지고 있으므로 약한 다항식 알고리즘이라고 볼 수 있다.
1.11.5. 아이디어 2
우리는 기존의 Ford-Fulkerson 알고리즘이 큰 용량을 가진 간선 대신 작은 용량을 가진 간선을 선택했을 때 발생하는 비효율성을 제거하기 위해 용량 스케일링(capacity scailing)을 사용했다. 그렇다면 기존의 Ford-fulkerson 알고리즘이 가지는 또다른 비효율성 문제는 무엇일까? 다시 한 번 예제를 살펴보자.
Figure 13: (Remind) A bad instance for the Ford-Fulkerson algorithm
위 그림에서 기존의 Ford-Fulkerson 알고리즘은 라는 짧은 경로 대신 라는 더 긴(비효율적인) 경로를 선택할 수 있다. 그래서 알고리즘이 가능한 짧은 경로를 먼저 찾도록 수정하여 기존의 알고리즘을 효율적인 알고리즘으로 변환할 수 있다. 이때 사용하는 유명한 알고리즘이 Edmonds-Karp 알고리즘이다.
1.12. 알고리즘 수정 (강한 알고리즘 설계)
Edmonds-Karp 알고리즘은 Ford-Fulkerson 알고리즘에 속한다고 볼 수 있다. 기존의 Ford-Fulkerson 알고리즘이 단순한 경로를 골랐다면, Edmonds-Karp 알고리즘은 이를 간선의 수가 최소인 경로로 범위를 줄인 것이다. 이전에 cycle이 없는 경로를 단순한 경로라고 정의했으며 cycle이 있는 경로가 있다면 반드시 cycle이 없는 단순한 경로 역시 존재하므로 간선의 수가 최소인 경로는 항상 단순한 경로임을 알 수 있다. 따라서 Edmonds-Karp 알고리즘은 다른 형태의 Ford-Fulkerson 알고리즘이며 최대 유량을 반환함을 알 수 있다.
1.12.1. Lemma 1
Edmonds-Karp 알고리즘의 Augmentation 실행 횟수는 이다.
1.12.2. Theorem 1
Edmonds-Karp 알고리즘의 실행 시간은 이다.
1.12.2.1. 증명
기존 Ford-Fulkerson 알고리즘에서는 단순한 경로를 찾기 위해 DFS 혹은 BFS를 사용하였다. 이번 Edmonds-Karp 알고리즘은 에서 로 도달하는 최단 경로를 찾는 것이기 때문에 DFS 대신 BFS를 사용하며 실행 시간은 (실제로는 )인 것을 알 수 있다. 따라서 각 반복마다 시간을 반복하며 Lemma 1에 따라 전체 알고리즘의 시간 복잡도는 이다.
왜 DFS 대신 BFS 일까?
Edmonds-Karp 알고리즘은 잔여 그래프에서 간선 수가 가장 적은 최단 경로를 우선적으로 선택하는 전략을 사용한다. 따라서 경로의 길이에 상관없이 탐색하는 DFS 대신, 항상 최단 경로를 보장하는 BFS를 사용하는 것이 최악의 경우를 방지하고 시간 복잡도를 줄이는 데 훨씬 효율적이다.
Edmonds-Karp 알고리즘은 입력 항목의 수인 노드의 수와 간선의 수에 대해 다항식 형태의 시간복잡도를 가지므로 강한 다항식 알고리즘이라 할 수 있다. 더 나아가서 이 최대 유량 문제(maximum flow problem)는 시간 내에 해결할 수 있다. 하지만 이 부분까지는 증명하지 않고 이것으로 최대 유량 문제에 대한 알고리즘 분석을 마치고자 한다.
2. Bipartite matching (Application of Network Flow 1)
Network Flow 도입에서 언급했듯이, Network Flow는 많은 분야에서 응용될 수 있다. 그 중 최대 유량 문제(maximum flow problem)를 서브루틴(subroutine)으로 사용하는 대표적인 최적화 문제, 이분 매칭(bipartite matching)에 대해 알아보고자 한다.
2.1. 이분 그래프 (Bipartite Graph)
2.1.1. Definition 1
정점들의 집합 를 와 로 분할하였을 때, , 을 만족하며 모든 간선들이 와 사이에 있는 경우, 즉 모든 간선들의 양쪽 끝 점들 중 하나는 에, 나머지 하나는 에 연결되어 있을 때 이 그래프를 이분 그래프(Bipartite Graph)라고 말한다.
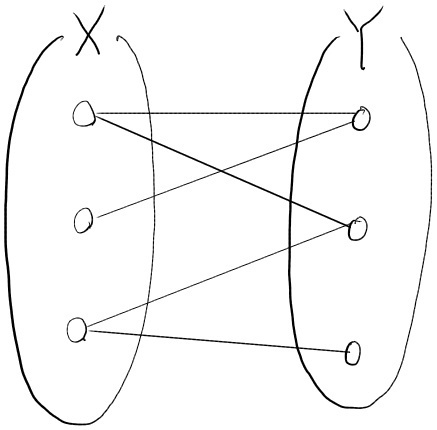
$\bigtriangleup$ Figure 14: (left) Bipartite graph and (right) non-Bipartite graph
2.1.2. Definition 2 ^8cc772
그래프 에서 모든 정점이 최대 한 번만 나타나는 간선들의 집합을 매칭 이라 한다.
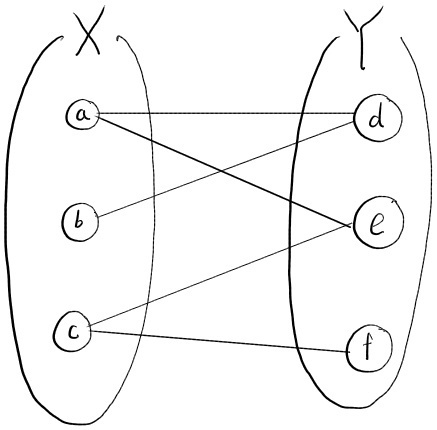
$\bigtriangleup$ Figure 15: Find matching in graph
위 그래프로 예를 들자면, Definition 2에 따라 {<a, e>, <b, d>, <c, f>}는 매칭이라고 할 수 있다. 선택한 간선들이 가지는 모든 정점들이 한 번만 나타나기 때문이다. 반대로 {<a, d>, <a, e>}는 정점 a가 두 번 나타났기 때문에 매칭이라고 볼 수 없다. 또한, {<a, e>, <b, d>} 집합은 정점 c, f가 나타나지 않았지만 Definition 2에 위배되지 않기 때문에 이 집합 역시 매칭이라고 볼 수 있다. 어떠한 간선도 선택하지 않은 경우 모든 정점이 0번(<1) 나타나기 때문에 매칭이라고 볼 수 있다.
2.2. Problem
(maximum matching) 이분 그래프 가 주어졌을 때, 최대 크기(maximum cardinality)를 가지는 매칭을 찾아라.
이번 문제를 풀 때 우리가 가정하는 것은 문제의 입력값으로 이미 , 로 이분할(bipartition)되어 있는 이분 그래프와 간선들의 집합 를 사용한다는 것이다.
2.3. Algorithm
2.3.1.1. Bipartite graph → flow network
앞서 언급했듯 우리는 최대 유량 문제(maximum flow)를 응용하여 이분 매칭(Bipartite matching) 문제를 해결하고자 한다. 우선 이분 매칭을 찾는 과정에서 한 가지 제약 사항이 있다. Definition 2에 따라 같은 정점을 공유하는 서로 다른 두 간선들을 선택할 수 없다는 것이다. 이러한 제약 사항 하에서 우리는 주어진 이분 그래프(Bipartite Graph)를 flow network로 개조할 것이다.
이분 그래프(Bipartite Graph)는 소스 노드와 싱크 노드가 없으며 무방향 그래프이고 각 간선에 용량 역시 할당되지 않았다. 우리는 이 세 가지 요인을 변형시켜 이분 그래프(Bipartite Graph)를 flow network로 바꿀 것이다.
우선 집합에 있는 정점에서 집합에 있는 정점으로 향하도록 무방향 간선들을 방향 간선들로 바꾼다. 이분 매칭 문제에서는 이분 그래프가 주어진다고 가정하기 때문에 모든 간선들은 집합 와 사이에 존재하며 따라서 모든 간선들을 에서 로 향하도록 만들 수 있다.
다음으로 이분 그래프에서 특정 간선을 선택한다는 개념을 flow network 상에서 해당 간선에 유량을 보내는 것으로 표현하고자 한다. 즉, 해당 간선을 고른다는 것을 표현하기 위해서는 해당 간선에 유량을 보낸다는 것만 알려주면 되므로 우리는 각 간선의 용량을 1로 설정하고자 한다.
마지막으로 flow network로 표현하기 위해 소스 노드와 싱크 노드를 설정해야 한다. 앞 단계에서 각 간선의 용량을 1로 설정함으로써 집합 에 있는 정점들은 유량이 1 부족한 상태가 되며 집합 에 있는 정점들은 유량이 1 초과한 상태가 된다. 소스 노드와 싱크 노드는 1개씩만 존재하며 집합 내부, 혹은 집합 내부에는 간선 연결이 없으므로 집합 에 있는 임의의 정점과 집합 에 있는 임의의 정점을 소스 노드와 싱크 노드로 설정할 수 없다. 따라서 유량 부족을 가지는 집합 에 유량을 보내줄 수 있도록 소스 노드를 추가하고 유량 초과를 가지는 집합 에서 유량을 빼낼 수 있도록 싱크 노드를 추가할 것이다. 즉, 집합 의 모든 정점들과 연결된 소스 노트 를 추가하고 집합 의 모든 정점들과 연결된 싱크 노드 를 추가하는 것이다. 그리고 추가된 간선들의 용량을 1로 설정함으로써 우리는 앞의 이분 매칭 제약 사항(같은 정점을 공유하는 서로 다른 두 간선이 선택될 수 없음)을 만족할 수 있다. 집합 의 한 정점 에서 나가는 간선이 두 개 이상 존재하여도, 소스 노드 에서 정점 로 들어오는 최대 유량은 1이므로 flow conservation 법칙 성립을 위해 하나의 간선만을 선택해야 한다.
앞서 제시한 Bipartite Graph를 flow network 그래프로 변형한 것은 다음과 같다.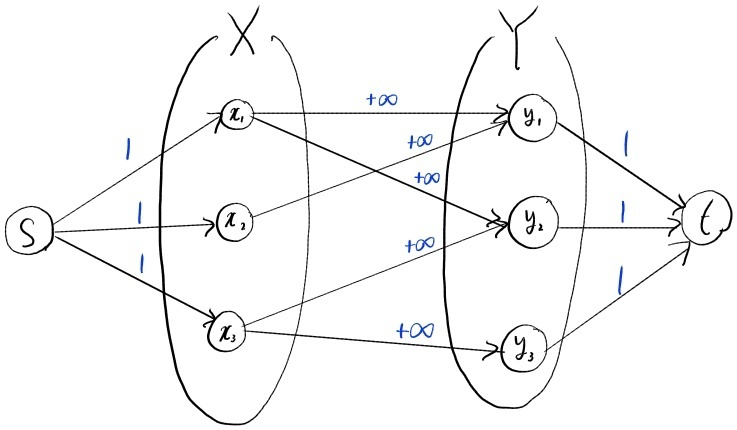
Figure 16: transformation Bipartite graph to flow network
Figure 16의 예시를 살펴보면 해당 Flow network의 최대 유량값은 3이며, 이는 Bipartite graph의 최대 매칭 크기(Maximum Cardinality)와 일치함을 알 수 있다. 즉, 최대 매칭 문제가 최대 유량 문제로 환원되어 해결될 수 있음을 확인할 수 있다.
한 가지 주목할 점은 Figure 16에서 집합 와 사이의 간선 용량이 로 설정되어 있다는 점이다. 물론 이렇게 설정하더라도 소스 노드 에서 로, 그리고 에서 싱크 노드 로 연결된 간선의 용량이 1이기 때문에, 유량 보존 법칙(Flow Conservation)에 의해 실제 간선에 흐를 수 있는 유량은 최대 1로 제한된다. 따라서 최종 결과에는 영향을 미치지 않는다.
굳이 용량을 로 설정한 이유는, 이렇게 함으로써 최소 컷(Min-Cut)과의 관계를 이용한 알고리즘 분석 및 증명 과정을 단순화할 수 있기 때문이다.
이러한 분석을 토대로, 다음과 같이 알고리즘을 설계한다.
2.3.1.2. Bipartite Matching Algorithm via Max-Flow Reduction
Beginning with , we construct a flow network as follows: first we direct all edges in from to . The capacities of these edges are set to . Then we add a source node and edges with unit capacity for all . Finally, we add a sink node and edges with unit capacity for all .
Once the flow network is constructed, we find a maximum integral flow . Let be the set of edges from to on which the flow value is nonzero. Output .
Bipartite Matching 알고리즘의 2가지 의문점
1. 프로그래밍 구현에서 를 어떻게 구현할 것인가? 프로그래밍 언어의 산술 연산은
int,float등과 같이 유한한 수에 대한 연산만을 지원하며, 와 같은 무한한 수에 대한 연산은 직접적으로 수행할 수 없다. 하지만 이를if문을 이용해 산술 연산 로직을 확장함으로써 해결할 수 있다. 예를 들어, 와 두 수를 더하는 프로그램을 구현한다고 가정해보자. 이때if문을 추가하여 두 수 중 하나라도 인지 확인하고, 만약 그렇다면 결과값으로 를 반환하고, 아니라면 일반적인 정수 산술 연산을 수행하도록 한다. 이러한 확인 과정은 상수 시간 내에 실행되므로, 전체 알고리즘의 시간 복잡도에 영향을 미치지 않으면서 논리적으로 완벽한 구현이 가능하다. 2. 결과가 정수(Integer)인 것을 어떻게 보장할 수 있는가? 앞선 알고리즘 설계에서 와 를 연결하는 간선들의 용량을 로 설정하였다. 일반적으로 포드-풀커슨 알고리즘은 용량이 정수일 때만 정수 해를 보장한다. 만약 소스 노드 에서 싱크 노드 로 향하는 경로의 병목 용량(Bottleneck Capacity)이 로 선택된다면, 이는 해당 네트워크의 최대 유량이 무한대임을 의미하며 정수성이 깨질 수 있다. 하지만 Bipartite Graph 환원 모델에서는 소스()에서 집합 로 가는 간선과, 집합 에서 싱크()로 가는 간선의 용량을 모두 1(정수)로 설정하였다. 이로 인해 전체 네트워크의 최대 유량은 유한한 값으로 제한된다. 따라서 탐색 과정에서 병목 용량으로 가 선택되는 상황은 발생하지 않으며, 병목 용량은 항상 유한한 정수(이 경우 1)가 선택되게 된다. 결론적으로 포드-풀커슨 알고리즘의 성질에 의해 최종적으로 구해지는 최대 유량 또한 정수임이 보장된다.
2.4. 알고리즘 분석
2.4.1. 알고리즘 정확성 분석
2.4.1.1. Lemma 1
모든 간선 에 대해, 간선 의 최대 유량 이면, 이 된다.
2.4.1.1.1. 증명
집합 , 의 임의의 정점 에 대해, 정점 로 들어오는 유일한 간선 는 1의 용량을 가지고 있으므로 flow conservation에 따라 이 성립한다. 이때 의 값은 정수값을 가지므로 의 값이 0이 아니라면 의 값은 1이 된다.
이제 를 입력 그래프의 최대 매칭 크기(maximum cardinality of a matching)라고 정의하자.
2.4.1.2. Lemma 2
알고리즘의 출력 크기 에 대해 가 성립한다.
2.4.1.2.1. 증명
입력 그래프의 최대 매칭을 이라 정의하자. flow network로 변환한 그래프에서 어떠한 유량도 보내지 않은 상태에서 가 포함하는 각 간선 에 대해 경로를 따라 1의 유량을 보낸다고 가정하자. 이때 어떠한 경로도 2번 이상 나타나지 않는다. 왜냐하면 를 매칭이라고 가정하였으므로 임의의 간선 는 최대 한 번만 나타나며 집합 의 정점 와 집합 의 정점 역시 에서 한 번만 나타났기 때문에 임의의 간선 와 역시 최대 한 번만 나타날 수 있다. 그래서 에 속한 간선 의 유량은 1이고, 속하지 않은 간선의 유량은 0으로 남아있다. 그리고 그 수만큼 소스 노트 와 싱크 노드 에 연결되어 있으므로 유효한 flow가 되며 이 과정에서 얻게 되는 유량값은 가 되는 것을 알 수 있다.
앞서 설명한 바와 같이 를 통해 구성한 유량은 유효한 유량(Feasible Flow) 중 하나이다. 최대 유량 는 정의상 모든 유효한 유량 중에서 값이 가장 크거나 같은 유량이므로, 특정 유효한 유량인 의 유량값보다 작을 수 없다. 따라서 가 성립한다. 이제 우리가 증명해야 하는 것은 알고리즘이 구한 최대 유량값 와 알고리즘이 출력할 최대 매칭 수 이 같다는 것이다. 우선, 인 cut 를 생각해보자. flow network 보조 정리에 따라 이 성립함을 알 수 있다. 우선 그래프의 모든 간선의 방향이 → 이므로 로 들어오는 유량의 값 는 0인 것을 알 수 있다. 에서 나가는 유량의 양은 Lemma 1에 따라 유량이 1인 간선들의 개수로 볼 수 있으며 이는 알고리즘이 출력하는 매칭의 크기, 즉 이 된다. 따라서 와 이 모두 성립함으로 Lemma 2 역시 성립함을 알 수 있다.
위 증명에 더해 은 보다 클 수 없으므로, 결국 가 되어 알고리즘이 찾은 해가 최적해임이 증명된다.
지금까지 알고리즘이 출력한 매칭의 크기가 최적 매칭의 크기와 일치함을 보였다. 이제부터는 알고리즘이 출력한 매칭이 우리가 설정한 정의에 따라 유효한 매칭인지 확인해보자.
2.4.1.3. Lemma 3
집합 의 임의의 정점 는 알고리즘이 출력한 매칭 의 간선들 중 최대 하나의 인접한 간선을 가진다.
2.4.1.3.1. 증명
귀류법(contradiction)을 이용해 증명해보자. 우선 매칭 의 두 개 이상의 간선들이 의 하나의 정점 와 인접하다고 가정해보자. Lemma 1에 따라 의 각 간선들의 유량은 1을 가지므로 알고리즘에서 찾은 최대 유량 에서 에서 나가는 총 유량 에 대해 가 성립한다. 그러나 에서 유량이 들어올 수 있는 간선은 하나이며 용량이 1이므로 로 들어오는 총 유량 에 대해 이 성립한다. 이 과정에서 flow conservation에 모순이 발생하게 된다.
Lemma 3의 증명 방식과 같은 방법으로 아래의 Lemma 4 역시 성립함을 알 수 있다.
2.4.1.4. Lemma 4
집합 의 임의의 정점 는 알고리즘이 출력한 매칭 의 간선들 중 최대 하나의 인접한 간선을 가진다.
2.4.1.5. Theorem 1
우리가 설계한 Bipartite matching algorithm은 최대 이분 매칭(Maximum Bipartite Matching)을 출력한다.
2.4.1.5.1. 증명
우리는 Lemma 2를 통해 알고리즘이 출력한 매칭 은 최적 매칭과 같거나 큰 크기의 매칭 크기를 반환하며 Lemma 3과 Lemma 4를 통해 출력된 매칭이 유효하다는 것을 알 수 있다. 따라서 해당 알고리즘은 최대 이분 매칭을 출력한다.
2.4.2. 알고리즘 실행 시간 분석
알고리즘의 입력으로 주어진 Bipartite graph 에 대해 정점의 수를 , 간선의 수를 이라 정의하자. () 그러면 알고리즘의 실행시간은 다음을 따른다.
2.4.2.1. Theorem 1
알고리즘의 실행 시간은 이다.
2.4.2.1.1. 증명
알고리즘에 따르면 주어진 Bipartite graph를 최대 유량 문제로 환원(Reduction)하기 위해 그래프를 수정한다. 이때 수정된 그래프의 정점의 수를 , 간선의 수를 이라 하자.
우선 임은 쉽게 알 수 있다. 기존 그래프에 소스 노드 와 싱크 노드 , 총 2개의 정점이 추가되기 때문이다.
간선의 경우, 집합 의 각 정점과 소스 노드 를 연결하는 간선들이 생성되고, 집합 의 각 정점과 싱크 노드 를 연결하는 간선들이 생성된다. 따라서 추가되는 총 간선의 수는 기존 그래프의 정점 개수인 과 같으므로 이 성립한다.
이제 이 그래프에서 Ford-Fulkerson 알고리즘을 수행한다. 일반적인 Ford-Fulkerson 알고리즘의 시간 복잡도는 이다. (여기서 은 간선 수, 는 소스 노드에서 나가는 총 용량). 우리가 구성한 그래프에서 소스 노드 에서 나가는 모든 간선의 용량은 1이다. 따라서 최대 유량값 는 소스 노드와 연결된 간선 용량의 총합인 를 초과할 수 없다. 즉, 이 성립한다. 이를 위 식에 대입하면 다음과 같은 시간 복잡도를 얻는다.
물론 Flow Network 구축 및 매칭 추출 시간도 고려해야 한다.
- Flow Network 구축: 정점 추가() 및 개의 새로운 간선과 개의 기존 간선(방향 설정)을 처리해야 하므로 의 시간이 소요된다.
- 매칭 추출: 알고리즘 종료 후 간선(개)을 순회하며 유량이 1인 간선을 찾으므로 의 시간이 소요된다. 이러한 부가적인 과정의 시간 복잡도 은 Ford-Fulkerson 알고리즘의 수행 시간 에 의해 지배(Dominated)된다. 따라서 전체 알고리즘의 최종 시간 복잡도는 이다.
시간 복잡도 분석 시 유의사항
시간 복잡도를 기술할 때는 입력의 크기(정점 , 간선 )와 수치적 크기(용량 )를 명확히 정의해야 한다. 본 알고리즘은 Bipartite Matching 문제를 최대 유량(Max Flow) 문제로 환원(Reduction)하여 해결한다. 이때 사용하는 Ford-Fulkerson 알고리즘은 구체적인 탐색 전략(DFS, BFS, Capacity Scaling 등)에 따라 , , 등 다양한 시간 복잡도를 가진다. 주의할 점은, 환원 과정에서 기존 이분 그래프에 소스()와 싱크() 노드 및 새로운 간선들이 추가되어 그래프의 구조가 변경된다는 것이다. 따라서 시간 복잡도를 최종적으로 서술할 때는 변환된 유량 네트워크의 정점()과 간선(), 그리고 용량()을 기존 그래프의 파라미터()로 정확하게 치환하여 표현해야 한다.
2.5. 정리
네트워크 유량(Network Flow)의 대표적인 응용 분야인 이분 매칭(Bipartite Matching) 문제를 다루어 보았다. 우리는 이 문제를 직접 해결하는 알고리즘을 고안하는 대신, 이미 해법이 알려진 최대 유량(Max Flow) 문제로 변형하여 푸는 방식을 택했다. 이러한 접근 방식을 ‘환원(Reduction)‘이라고 하며, 구체적인 과정은 다음과 같다.
- 변환(Convert): 주어진 이분 매칭 문제를 유량 네트워크(Flow Network) 형태로 변환한다.
- 해결(Solve): 변환된 문제에 대해 이미 검증된 Ford-Fulkerson 알고리즘을 수행하여 최대 유량을 구한다.
- 해석(Interpret): 구해진 최대 유량 결과를 역으로 추적하여 원래 문제인 이분 매칭의 해답(매칭 집합)으로 변환한다. 우리는 해결 단계(2)에서 사용되는 Ford-Fulkerson 알고리즘이 정확하다는 가정하에, 앞서 증명한 보조 정리(Lemma)들을 통해 이 변환 및 해석 과정이 논리적으로 타당함을 확인하였다. 결론적으로, 이분 매칭 문제는 최대 유량 문제로 성공적으로 환원되어 해결될 수 있다.
3. Application of Max-Flow Min-Cut theorem
이전까지 이분 매칭 문제(Bipartite Matching Problem)를 flow network 문제로 환원시켜 해결하는 방법을 알아보았다. 그리고 flow network 문제는 Ford-Fulkerson 알고리즘을 통해 해결될 수 있으며 Ford-Fulkerson 알고리즘은 최대 유량-최소 컷 이론(Max-Flow Min-Cut theorem)에 기반하여 설계되었다. 지금부터는 최대 유량-최소 컷 이론을 응용한 사례를 알아보고자 한다.
3.1. Reminder
시작에 앞서 이전의 Ford-Fulkerson 알고리즘의 정확성 분석에서 사용된 주요 Lemma와 Theorem, 그에 따른 corollary에 대해 다시 정리해보자.
3.1.1. Lemma 1
경로를 가지지 않는 잔여 그래프 를 만족하는 유량 가 있다면, 인 컷 가 항상 존재한다.
Ford-Fulkerson 알고리즘이 종료되는 시점(더 이상 에서 로 유량을 증가시킬 수 없는 상태)에 도달하면 이때의 최대 유량값()과 같은 용량을 가진 cut이 존재함을 설명한다.
3.1.2. Theorem 1
(Max-Flow Min-Cut Theorem) 모든 flow network에서 최대 유량값은 cut의 최소 용량과 같다.
이 정리는 Ford-Fulkerson 알고리즘의 정확성 분석을 통해 증명할 수 있다. 즉, 알고리즘이 반환하는 최대 유량 의 값과 알고리즘 종료 시 잔여 그래프에서 유도되는 cut 의 용량 이 같음을 보여주었다. 또한 최대 유량 와 임의의 cut 에 대해 가 성립한다. 따라서 이므로 theorem 1이 성립함을 알 수 있다.
3.1.3. Theorem 2
Ford-Fulkerson 알고리즘이 다항 시간에 실행되도록 구현할 수 있다.
이전에 Ford-Fulkerson 알고리즘이 다항 시간에 실행될 수 있도록 하는 2가지 구현 방법을 알아보았다. 용량 스케일링(Capacity Scailing)을 사용한 Ford-Fulkerson 알고리즘은 실행시간을 가지고, Edmonds-Karp Algorithm을 통해 의 실행시간을 가질 수 있다. 두 실행 시간 모두 입력 항목 수 혹은 입력 비트 수에 대한 다항식으로 표현되었으므로 다항 시간에 실행된다고 볼 수 있다.
3.1.4. Corollary 1
소스 노드 와 싱크 노드 를 가진 flow network가 주어졌을 때, 최소 cut(minimum cut)을 다항 시간에 찾을 수 있다.
간단히 알고리즘을 세우자면 다음과 같다.
- 다항 시간 flow network 알고리즘 실행: Edmonds-Karp 알고리즘이나 용량 스케일링을 적용한 Ford-Fulkerson 알고리즘과 같은 다항 시간 버전 중 하나를 실행한다.
- 잔여 그래프 구성 및 탐색: 알고리즘 실행 완료 후, 최종 잔여 그래프()를 구성한다.
- 집합 식별: 소스 노드 로부터 도달할 수 있는 모든 정점들의 집합을 로 정의한다.
- 집합 식별: 의 여집합(나머지 모든 정점들)을 로 정의한다.
- 결과: 이렇게 식별된 컷 가 주어진 유량 네트워크에서 찾을 수 있는 최소 컷이 된다.
이를 통해 최대 유량 문제(Max-flow problem)뿐만 아니라 최소 컷 문제(Min-cut problem) 역시 다항 시간에 해결될 수 있다는 것을 알 수 있다.
3.2. 실행 가능성 문제(feasibility problem)
이전까지 우리는 어떤 그래프와 특정 제약 조건들이 주어졌을 때, 해당 조건들을 만족하는 해들 중 최대 혹은 최소값을 가지는 해를 찾는 최적화 문제에 집중하였다. 지금부터는 단순히 해의 유무에 대해서만 관심을 가지는 실행 가능성 문제(feasibility problem)에 집중하고자 한다.
3.2.1. Definition 1
이분 그래프(bipartite graph) 에서 집합 에 속하는 모든 정점이(여기서는 그래프 왼쪽 부분의 모든 정점) 매칭 에 속해있을 경우, 이러한 매칭 을 왼쪽 완전 매칭(left-perfect matching)이라 정의한다.
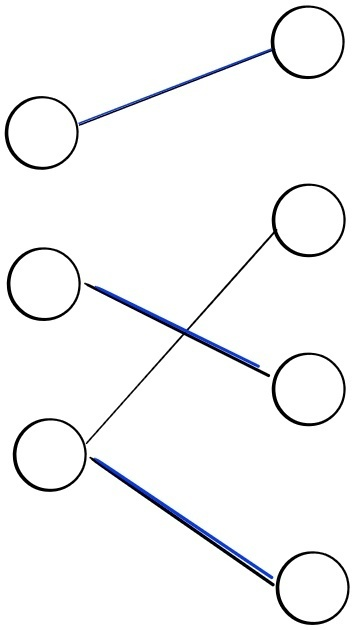
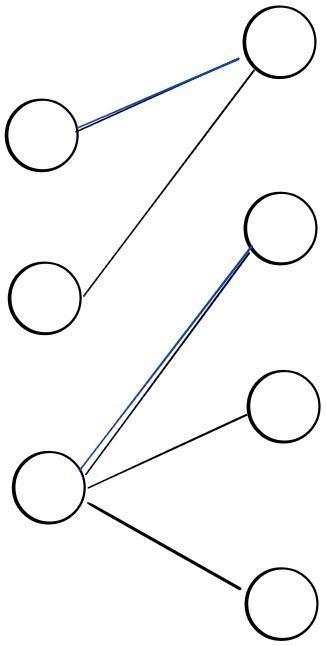
Figure 17: the left-perfect matching(left) and non-left-perfect matching(right)
예를 들어 위 왼쪽 그림은 파란색으로 칠해진 matching 간선들이 모두 왼쪽 정점들을 포함하고 있으므로 왼쪽 완전 매칭이라 할 수 있지만 오른쪽 그림의 경우 어떠한 matching 간선 조합들도 왼쪽 정점들을 모두 포함할 수 없기 때문에 왼쪽 완전 매칭이 될 수 없다.
우리는 이분 그래프가 주어졌을 때, “왼쪽 완전 매칭을 찾아라”가 아닌 “왼쪽 완전 매칭이 존재하는가”에 대한 질문에 답을 할 것이다. 그리고 이 질문에 대한 답을 위해서는 인증서(certification)가 필요하다.
우선 왼쪽 완전 매칭이 존재할 때의 인증서는 비교적 쉽게 알 수 있다. 바로 왼쪽 완전 매칭 자체를 보여주면 된다. 우리는 Bipartite matching 문제에서 이미 최대 크기 매칭을 구하는 방법을 알고 있다. Bipartite matching 알고리즘을 이용하여 최대 매칭을 구한 후, 해당 매칭이 유효한 매칭인지 확인한 후 왼쪽 부분의 모든 정점을 포함한다는 것을 보여준다면 왼쪽 완전 매칭이 존재한다고 할 수 있다.
하지만 오른쪽 그림과 같이 왼쪽 완전 매칭이 존재하지 않을 경우, 해당 사실을 보여줄 인증서로 어떤 것을 선택해야 할지 생각해야 한다. 단순히 2개의 간선 집합만을 보여주는 것만으로는 충분한 근거가 되지 않기 때문이다. 따라서 왼쪽 완전 매칭이 존재하지 않는 구조적 이유에 집중하여 인증서를 찾아야 한다.
3.3. 왼쪽 완전 매칭 존재 여부 결정
3.3.1. Definition 1
임의의 정점 집합 에 대해(), 를 집합 의 임의의 정점과 인접한 모든 정점들의 집합이라 정의하자. 즉, 이라 하자.
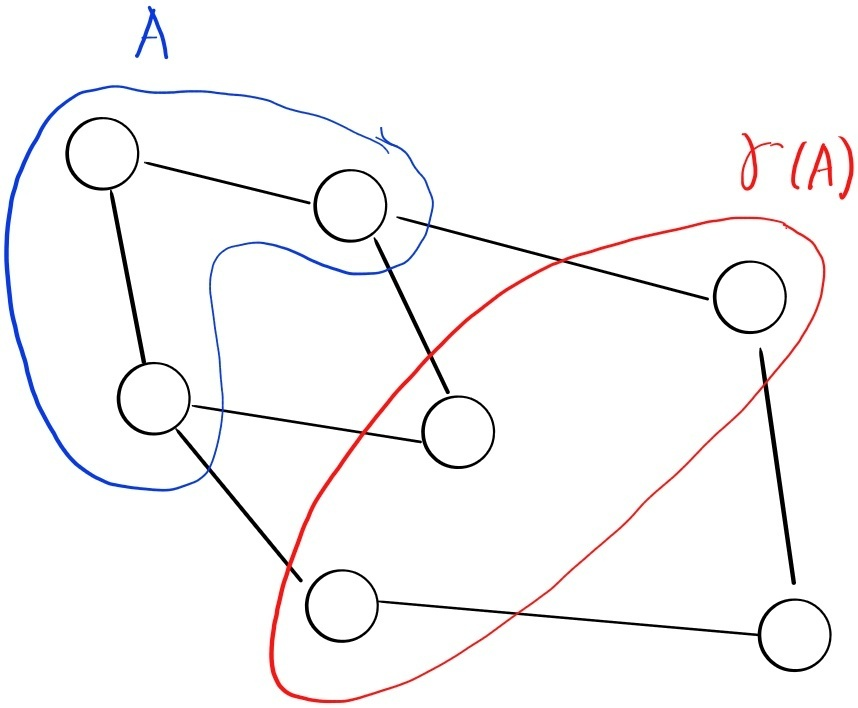
$\bigtriangleup$ Figure 18: Definition of $\gamma(A)$
예를 들어 위 그림에서 집합 (파란색으로 칠해진 부분)에 속하는 정점들과 인접한 3개의 정점 집합이 (빨간색으로 칠해진 부분)에 속한다고 볼 수 있다.
이제 이전의 ‘아니오’ 인스턴스(instance)를 입증하기 위한 유효한 인증서를 제시하기 위해 다음과 같이 홀의 정리(Hall’s theorem)를 이용할 수 있다.
3.3.2. Theorem 1
(Hall’s Theorem) 이분 그래프 에 대해, 왼쪽 완전 매칭이 존재하기 위한 필요충분조건은 다음과 같다. 왼쪽 정점들의 집합 의 임의의 부분집합 에 대해, 에 인접한 정점들의 집합 의 크기가 의 크기보다 크거나 같아야 한다.()
3.3.2.1. 증명
- () 방향 증명 왼쪽 완전 매칭이 존재한다면 가 성립함을 보이자. 이분 그래프 가 왼쪽 완전 매칭 을 가진다고 가정하자. 집합 의 임의의 부분집합 를 선택했을 때, 에 속한 모든 정점은 매칭 에 의해 의 서로 다른 정점들과 일대일로 연결된다. 매칭된 의 정점들의 집합을 라 하면, 이고 이다. 따라서 가 성립한다.
- () 방향 증명 임의의 에 대해 가 성립한다면 왼쪽 완전 매칭이 존재함을 보이자. 이를 위해 최대 유량-최소 컷 정리(Max-Flow Min-Cut Theorem)를 사용한다. 앞서 설계한 flow network(모든 용량 1, 간선 용량 )에서 임의의 컷 를 고려하고, 이 컷의 용량 를 계산해보자. () 편의상 라고 정의하자. 이때 이며 가 성립한다고 가정한다.
-
Case 1: 의 이웃 중 에 포함된 정점이 존재하는 경우 () 이 경우 에 포함된 정점(의 원소)에서 에 포함된 정점(의 원소)으로 가는 간선이 존재한다. 이 간선의 용량은 이므로, 컷의 용량 가 된다. 이는 자명하게 보다 크다.
-
Case 2: 의 모든 이웃이 에 포함된 경우 () 우선 cut 용량 계산을 위해 고려해야 하는 간선 종류는 다음과 같다.
- 소스 노드 에서 로 가는 간선들 소스 노드 는 에 있으며 의 정점 중 에 속하지 않는 정점들은 에 있으므로 컷 용량 계산 시 고려해야 한다. 이때 간선의 용량은 1이므로 이들의 용량 합은 이다.
- 에서 로 가는 간선들 싱크 노드 는 항상 에 속하므로 에 속하는 정점들에서 로 가는 간선들을 컷 용량 계산 시 고려해야 한다. 이때, 가 성립하며 의 모든 정점들은 에 속하므로(는 의 이웃 정점들의 집합이며 가 성립하기 때문) 가 성립한다. 따라서 이들의 용량 합 가 성립한다.
- 로 가는 간선들
Case 2에서 설정한 가정 에 따라, 집합 와 연결된 내 모든 정점들이 에 속하므로 컷 용량 계산 시 고려해야 하는 간선은 존재하지 않는다.
 Figure 19: example of left-perfact matching
예를 들어, 위의 그림에서 집합 , 집합 인 것을 알 수 있다. 여기서 이며 이 정점들 모두 집합 에 포함되어 있음을 알 수 있다. 이를 바탕으로 위 그래프의 cut 용량을 계산해보면 소스 노드 에서 에 포함되어 있지 않은 정점 으로 가는 간선 , 집합 에 포함되어 있는 정점들에서 싱크 노드 로 가는 정점들과 연결된 간선 이므로 이다.
위 예시의 경우 이므로 이지만, 만약 이 에 포함될 경우 용량은 더 커질 수 있다. 하지만 우리가 증명할 것은 컷 용량의 하한선에 집중할 것이기 때문에 이러한 추가적인 간선들에 대해서는 고려하지 않을 것이다.
Figure 19: example of left-perfact matching
예를 들어, 위의 그림에서 집합 , 집합 인 것을 알 수 있다. 여기서 이며 이 정점들 모두 집합 에 포함되어 있음을 알 수 있다. 이를 바탕으로 위 그래프의 cut 용량을 계산해보면 소스 노드 에서 에 포함되어 있지 않은 정점 으로 가는 간선 , 집합 에 포함되어 있는 정점들에서 싱크 노드 로 가는 정점들과 연결된 간선 이므로 이다.
위 예시의 경우 이므로 이지만, 만약 이 에 포함될 경우 용량은 더 커질 수 있다. 하지만 우리가 증명할 것은 컷 용량의 하한선에 집중할 것이기 때문에 이러한 추가적인 간선들에 대해서는 고려하지 않을 것이다.
이러한 내용을 바탕으로 수식을 작성하면 다음과 같다.
여기서 가정에 의해 $\gamma(A) \subseteq Y \cap S$이므로, $|Y \cap S| \geq |\gamma(A)|$가 성립한다. 또한, 문제의 조건인 Hall's condition ($|\gamma(A)| \geq |A|$)을 적용하면 다음과 같이 전개된다.
결론 모든 경우에 대해 최소 컷의 용량은 이상이다 (). 소스 에서 나가는 간선의 총 용량이 이므로, 최대 유량은 를 넘을 수 없다. 따라서 최소 컷의 용량은 정확히 이며, 최대 유량-최소 컷 정리에 의해 최대 유량 또한 가 된다. 최대 유량이 라는 것은 의 모든 정점이 매칭에 참여한다는 뜻이므로, 왼쪽 완전 매칭이 존재한다.
→ 간선들의 용량을 +로 설정한 이유
우리는 증명 과정에서 임의로 로 가는 모든 간선들의 용량을 1이 아닌 로 설정하였다. 이는 다음과 같은 두 가지 이유 때문이다.
- 결과 보존: 와 간선의 용량이 1이므로, 유량 보존 법칙(Flow Conservation)에 의해 중간 간선의 용량이 아무리 커도 실제 흐르는 유량은 최대 1로 제한된다. 즉, 결과값에 영향을 주지 않는다.
- 증명의 단순화: 만약 의 어떤 정점이 집합 에 포함되어 있지 않다면(즉, 에 있다면), 간선이 컷을 가로지르게 된다. 이때 용량이 이므로 해당 컷의 용량은 무한대가 되어 최소 컷(Min-Cut)의 후보에서 자동적으로 제외된다. 덕분에 우리는 중간 간선이 잘리지 않는 케이스()만 고려하면 되므로, Hall’s Theorem을 훨씬 쉽게 증명할 수 있다.
이제 우리는 ‘왼쪽 완전 매칭이 존재하냐’라는 질문의 ‘아니오’ 인스턴스에 대해 증명할 수 있는 인증서를 가지고 있다. 이분 그래프 가 왼쪽 완전 매칭을 가지지 않는다면 이분 매칭 알고리즘에서 구성된 그래프가 보다 작은 최대 유량을 가진다는 것을 의미하며 이는 최소 cut 용량이 보다 작은 cut이 존재한다는 것을 의미한다. 이러한 cut과 집합과의 교집합을 취하여 집합 를 선택하게 되면 홀의 정리(Hall’s theorem)에 위반되었다는 인증서(certification)를 생성할 수 있으며 왼쪽 완전 매칭이 존재할 수 없다고 주장할 수 있다. 이를 다음과 같이 정리할 수 있다.
3.3.3. Corollary 1
주어진 이분 그래프 에서 왼쪽 완전 매칭이 존재하지 않는다면, 인 집합 를 다항 시간 내에 찾을 수 있다.
3.3.3.1. 증명
이분 매칭 문제를 해결하기 위해 구성한 Flow Network에서 최소 컷을 라 하고, 그 용량을 라 하자.
그래프 가 왼쪽 완전 매칭을 가지지 않는다고 가정하면, 최대 유량-최소 컷 정리에 의해 최소 컷의 용량은 왼쪽 정점의 개수보다 작아야 한다.
이 부등식은 가 유한한 값임을 의미한다. 우리가 구성한 네트워크에서 간선의 용량은 이므로, 컷의 용량이 유한하다는 것은 간선이 컷을 가로지르지 않음을 뜻한다. 라 정의할 때, 이는 곧 의 모든 이웃이 에 포함됨()을 내포한다.
이제 컷의 용량 계산식을 전개하면 다음과 같다. (앞선 Hall’s Theorem 증명 과정 참고)
위의 두 부등식을 결합하면 다음과 같은 결과를 얻는다.
양변에서 를 소거하고 정리하면:
즉, 가 성립한다.
우리는 최대 유량 알고리즘(예: Edmonds-Karp, capacity-scailing 등)을 통해 다항 시간(Polynomial Time) 내에 최대 유량을 구할 수 있으며, 이 과정에서 잔여 그래프(Residual Graph)를 이용해 최소 컷 또한 다항 시간 내에 찾을 수 있다.
따라서 최소 컷을 찾은 뒤 를 계산하면, 조건을 만족하는 집합 를 다항 시간 내에 찾을 수 있음이 증명된다.
3.4. 정리
지금까지 최대 유량-최소 컷 정리(Max-Flow Min-Cut Theorem)를 기반으로 홀의 정리(Hall’s Theorem)를 유도하고, 이를 통해 왼쪽 완전 매칭의 존재 여부를 판단하는 방법에 대해 알아보았다. 특히, 홀의 정리는 매칭이 존재하지 않을 때 그 이유를 수학적으로 입증해 주는 인증서(Certificate) 역할을 하며, 이는 추후 실현 불가능성(Infeasibility)을 증명하거나 이를 찾는 알고리즘의 중요한 이론적 토대가 된다.
4. Circulation problem (Application of Network Flow 2)
최대 유량 문제(Max-Flow problem)에서는 소스 노드 와 싱크 노드 가 존재하며 이 두 정점을 제외한 모든 노드에서 flow conservation이 성립하는 최대 유량값을 찾았다. 이번 순환 문제(Circulation problem)에서는 소스 노드와 싱크 노드 구분 없이 모든 정점에서 flow conservation이 성립하는 유량의 존재 여부를 알아볼 것이다. 순환 문제에서는 기존의 용량 제한()뿐만 아니라 반드시 흘려보내야 하는 최소 유량 하한선(lower bound)이 제약 조건으로 추가될 것이다.
4.1. 도입
우선 최소 유량 하한선을 설정하기 전, 각 정점마다 공급(supply) 또는 수요(demand)를 가지는 flow network부터 알아보자. 다음 그림을 살펴보자.
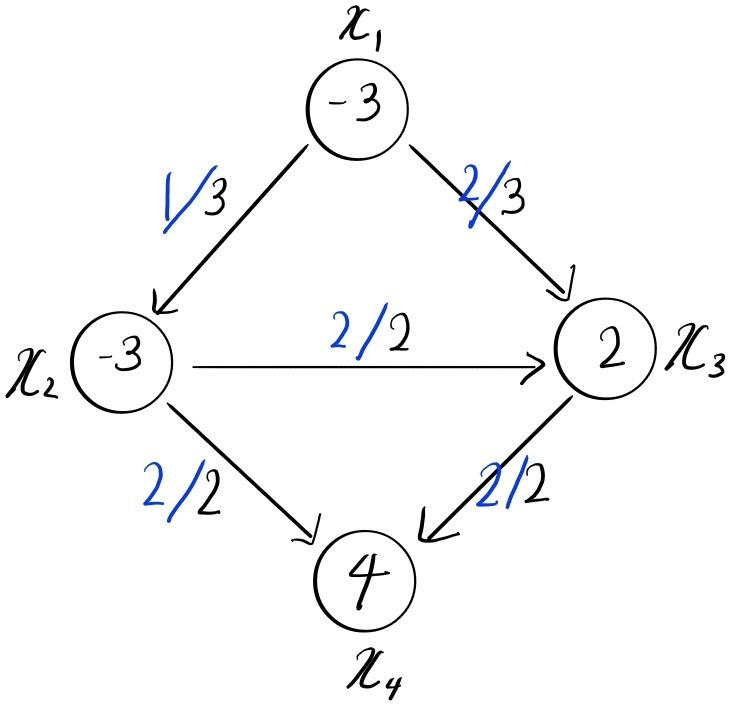
Figure 20: Flow Network with Demand or Supply
위 그림에서 각 간선 당 용량이 주어진 기존의 flow network에 각 정점 당 수요 또는 공급의 크기가 지정되어있다. +일 경우 공 해당 정점으로의 순유입(순수요)을 의미하고 -일 경우 해당 정점에서의 순유출(순공급)을 의미한다.
여기서 우리가 알고 싶은 것은 해당 수요와 공급 조건을 만족하는 flow network의 존재 여부이다. 위의 그림에서 파란색으로 적은 수만큼 해당 간선에 유량값을 할당하면 수요와 공급 조건을 만족하며 실현 가능성에 대한 정답은 ‘예’이다.
하지만 우리는 Flow Network의 여러 응용 분야에 대해 알아보고 있으며 이러한 분야들에서는 대부분 ‘예’ 인스턴스일 경우, 해당 유량(정답) 역시 알아보고자 한다. 따라서 우리는 실현 가능성과 실현 가능할 경우의 최적 해를 출력하는 알고리즘을 설계하고자 한다.
4.2. Circulation 정의
4.2.1. Definition 1
도입부에서 언급했던 내용을 공식적으로 정의하고자 한다. 각 정점 당 수요 가 배정될 것이며 이면 수요(순유입량)을 의미하고, 이면 공급(순유출량)을 의미한다.
4.2.2. Definition 2
각각의 간선 에 대해 용량 를 가지고 각각의 정점 에 대해 수요 를 가지는 Flow Network가 모든 간선에 대해 음이 아닌 실수로의 함수, 즉 에 대해 다음 조건이 만족하면 Circulation이라 정의한다.
- (Capacity Condition) 각각의 간선 에 대해 가 성립한다.
- (Demand Condition) 각각의 정점 에 대해 가 성립한다.
4.3. Problem
(Circulation Problem) 수요 를 가지는 Flow Network가 주어졌을 때, 실현 가능한 Circulation의 존재 여부를 결정하라.
4.4. Algorithm
우선 실현 가능한 Circulation이 존재하는지 직관적으로 확인할 수 있는 방법이 있다. 특정 간선에 유량을 흘려보낼 경우, 하나의 정점이 유량을 생성할 경우 다른 정점은 같은 양의 유량을 흡수하게 된다. 따라서 실현 가능한 Circulation이 존재하는 그래프는 모든 정점의 수요의 합이 0이 되어야 함을 알 수 있다. 이를 아래와 같이 공식화할 수 있다.
4.4.1. Lemma 1
각각의 간선 에 대해 용량 를 가지고 각각의 정점 에 대해 수요 를 가지는 그래프 가 실현 가능한 순환(Circulation)을 가진다면 이 성립한다.
4.4.1.1. 증명
를 실현 가능한 순환이라고 가정하자. 앞에서 정의한 Circulation의 수요 조건(Demand Condition)에 따라 모든 정점 에 대해 가 성립한다. 여기서 모든 정점 에 대해 이 성립한다. 앞에서 설명했던 것과 같이 모든 간선 는 두 개의 정점을 가지며, 해당 간선의 유량값 중 한 번은 로, 다른 한 번은 로 나타나게 된다. 은 +1의 계수를 가지고 는 -1의 계수를 가지므로 이러한 값들을 모두 합치면 최종적으로 0이 된다. 따라서 이 성립함을 알 수 있다.
4.4.2. Circulation problem Max-Flow problem
앞에서 이분 매칭 문제를 최대 유량 문제로 환원하여 해결했던 것과 같이 이번 순환 문제 역시 최대 유량 문제로의 환원을 통해 해결할 수 있다. 그렇기 때문에 이번 순환 문제 역시 Flow Network의 한 응용 분야라고 부른다.
그래서 이제부터 순환 문제에 주어진 그래프를 약간 수정하여 최대 유량 문제로 환원하여 문제를 해결할 것이다. 우선 순환 문제와 최대 유량 문제는 다음과 같은 차이점이 존재한다.
- Demand Condition vs Flow Conservation
- 소스 노드 와 싱크 노드 의 유무
- 실현 가능성 문제 vs 최적화 문제
이제 이러한 차이점들을 제거하여 순환 문제를 최대 유량 문제로 변환해보자.
우선, 순환 문제에서 주어진 그래프는 각각의 정점마다 수요값()이 존재하며 이는 몇몇 정점들이 0보다 순유입량을 받아야 한다는 것을 의미한다. 하지만 최대 유량 문제에서 0보다 순유입량을 받을 수 있는 정점은 싱크 노드 하나뿐이다. 이를 해결하기 위해 초과된 유량을 가지는 노드와 추가할 싱크 노드 를 간선으로 연결하여 로 보내야 한다. 이때 새롭게 추가된 간선들의 용량은 각각과 연결된 기존 정점의 수요값으로 설정한다.
공급값 역시 위와 같은 방식으로 소스 노드 를 생성하여 해결할 수 있다. 음수 수요값을 가지는 정점들과 새롭게 추가할 소스 노드 를 연결하고 각각의 간선들의 용량은 각각의 기존 정점들의 공급값(=)으로 설정한다.
위와 같은 방식을 통해 전에 보았던 Circulation 그래프를 수정하면 다음과 같다.
 Figure 21: transformation of circulation problem to max-flow problem
이때, 기존 그래프에서 실현 가능한 순환이 되도록 기존 간선들의 유량을 설정한 후, 추가한 간선들을 포화시키면(즉, 추가한 간선들의 유량을 각각의 용량과 같은 값으로 설정하면), Flow network의 Capacity Condition과 Flow Conservation 모두 만족한다.
Figure 21: transformation of circulation problem to max-flow problem
이때, 기존 그래프에서 실현 가능한 순환이 되도록 기존 간선들의 유량을 설정한 후, 추가한 간선들을 포화시키면(즉, 추가한 간선들의 유량을 각각의 용량과 같은 값으로 설정하면), Flow network의 Capacity Condition과 Flow Conservation 모두 만족한다.
추가한 간선들의 용량
소스 노드 와 싱크 노드 와 연결된 새로운 간선들의 용량은 해당 간선들과 연결된 기존 정점의 수요값과 일치시켰다. 이를 바탕으로 기존 실현 가능한 그래프의 유량 초과/부족 문제를 해결하여 Flow Conservation을 만족시킬 수 있으며, 각각의 정점이 가지는 수요값/공급값보다 큰 값을 보내거나 받을 수 없게 설정함으로써 앞으로 우리가 진행할 증명을 용이하게 하였다.
이를 통해 실현 가능한 순환 그래프를 위의 조건과 같은 Flow Network 그래프로 변환한다면 추가된 모든 간선이 포화된 최대 유량이 존재함을 알 수 있다.
그렇다면 역으로 변형한 Flow Network에서 추가된 양쪽 간선들(와 연결된 간선들)이 모두 포화된 최대 유량이 존재한다고 가정해보자. 이 상태가 원래의 순환 문제에서 어떤 의미를 갖는지 역으로 생각해볼 필요가 있다.
- 간선 삭제를 통한 직관적 이해 위의 변형된 Flow Network 그림에서, 유량이 흐르고 있는 상태에서 소스 노드 와 그 연결 간선을 제거한다고 가정하자. 에서 정점 으로 3만큼의 유량이 들어오고 있었다면( 포화), 이 연결이 끊기는 순간 은 유량 보존(Flow Conservation)을 유지하기 위해 스스로 3만큼의 유량을 생성해내야 한다. 즉, 은 3의 공급량() 을 가지게 된다. 우리가 애초에 의 간선 용량을 의 공급량()으로 설정했기 때문에, 이는 기존 순환 그래프의 공급 조건을 정확히 만족시킨다. 이는 싱크 노드 를 제거했을 때 수요량()을 만족하는 원리와도 동일하다.
- 양쪽 간선(와 연결된 간선과 와 연결된 간선)이 모두 포화되는 이유
여기서 한 가지 의문이 남는다. “Flow Network에서 최대 유량을 찾았을 때, 와 연결된 간선들이 모두 포화된다면 와 연결된 간선들도 반드시 모두 포화되는가?”
이는 앞서 증명한 Lemma 1(필요조건)을 통해 보장된다. 실현 가능한 순환이 존재하기 위해서는 모든 수요의 합이 0이어야 한다().
- 와 연결된 간선 용량의 합 = 총 공급량
- 와 연결된 간선 용량의 합 = 총 수요량 총 공급량과 총 수요량이 같으므로, 한쪽이 모두 포화되는 최대 유량이라면 반대쪽 역시 반드시 포화되어야 한다.
- 결론 따라서 변환된 Flow Network에서 양쪽 간선이 모두 포화된 최대 유량을 찾는 것은 원래 그래프에서 실현 가능한 순환을 찾는 것과 논리적으로 동치(equivalent)이다.
4.4.3. 표기법 설정
알고리즘 설계에 앞서 알고리즘에서 사용될 기호를 설정하고자 한다.
, 로 설정한다. 즉, 는 공급이 있는 정점들의 집합, 는 수요가 있는 정점들의 집합으로 설정한다.
또한, 실현 가능한 순환 그래프에서 를 수요의 합, 로 설정한다. 이때 실현 가능한 순환 그래프에서는 수요의 합과 공급을 합이 같으므로 로 설정할 수 있다.
순환 문제를 최대 유량 문제로 환원시키는 과정에서 소스 노드와 싱크 노드를 생성한다. 이때 생성된 소스 노드와 싱크 노드를 각각 슈퍼 소스 노드 와 슈퍼 싱크 노드 로 설정한다.
슈퍼 소스 노드, 슈퍼 싱크 노드 이름의 유래
기존의 최대 유량 문제는 단일 소스에서 유량이 생성되고 단일 싱크에서 소비된다고 가정한다. 반면, 순환 문제(Circulation Problem)에서는 유량을 공급하거나 소비하는 정점이 여러 개 존재한다. 이를 최대 유량 문제로 환원할 때, 흩어져 있는 여러 공급 정점들의 역할을 하나로 통합(Aggregate)하여 모든 유량을 공급해 주는 가상의 노드를 추가하게 되는데, 이를 슈퍼 소스 노드라고 부른다. 슈퍼 싱크 노드 역시 여러 수요 정점들을 하나로 통합하여 받아낸다는 같은 원리에서 유래되었다.
4.4.4. Algorithm of Circulation Problem
우리가 설계할 알고리즘은 다음의 순서를 따른다.
- 기존 그래프에서 모든 수요의 합에 대해 이 성립하는지 확인한다. 만약 모든 수요의 합이 0이 아니라면 실현 가능한 순환을 만들 수 없으므로 바로 ‘아니오’라고 출력한다.
- 이제 순환 문제를 최대 유량 문제로 환원시키기 위해 Flow Network를 다음과 같이 구성한다.
- 슈퍼 소스 노드 와 슈퍼 싱크 노드 를 생성한다.
- 기존 그래프의 모든 간선들을 그대로 남겨 둔다.
- 각각의 공급 정점 를 슈퍼 소스 노드 와 연결하며 용량은 로 설정한다.
- 각각의 수요 정점 를 슈퍼 싱크 노드 와 연결하며 용량은 로 설정한다.
- 구성한 Flow Network에서 최대 유량 를 구한다. (Ford-Fulkerson 알고리즘 사용)
- 최대 유량 가 추가된 양쪽 간선들을 모두 포화시키는지, 즉 를 만족하는지 확인한다. 양쪽 간선들의 용량의 합은 수요의 합/공급의 합과 같으므로 를 통해 포화 여부를 알 수 있다. 포화되었을 경우, 와 를 제거하였을 때 기존 정점들의 수요 조건을 만족하므로 실현 가능한 순환이 존재하고 ‘예’를 출력한다. 포화되지 않았을 경우, 와 를 제거하였을 때 기존 정점들의 수요 조건이 만족되지 않으므로 실현 가능한 순환이 존재하지 않고 ‘아니오’를 출력한다.
4.5. 알고리즘 분석
4.5.1. 알고리즘 정확성 분석
순환 문제 역시 최대 유량 문제로의 환원을 통해 해결하고 있다. 최대 유량을 구하는 과정에서는 이미 정확하다고 알고 있는 Ford-Fulkerson 알고리즘을 사용할 수 있다. 따라서 우리는 구해진 최대 유량이 일 경우 정말로 실현 가능한 순환이 존재하는지 증명해야 한다.
4.5.1.1. Theorem 1
순환 문제 알고리즘은 정확한 값을 반환한다.
4.5.1.1.1. 증명
알고리즘에서 구한 최대 유량값 이 성립한다고 가정하자. 이제 구성한 Flow Network에서 cut을 고려해보자. 우리는 슈퍼 소스 노드 와 이외 모든 정점들로 나눌 것이다. 즉, 인 cut을 설정하며, 이때 가 된다. 이는 최대 유량값과 같은 용량을 가지는 cut을 찾았다는 것을 의미하며, 이는 소스 측에서 싱크 측으로 가는 모든 간선에 간선에 대해 용량과 같은 유량이 흘러야 한다는 것을 의미한다. 따라서 각각의 에 대해 가 성립한다.
이와 비슷하게 슈퍼 싱크 노드 와 이외 모든 정점들로 나뉘어진 cut 를 고려해보자. 이므로 각각의 간선 에 대해 가 성립한다.
Network Flow에서 Flow conservation이 성립하므로 모든 정점 에 대해 이 성립한다. 이제 알고리즘에서 유도될 실현 가능한 순환을 이라 설정하자. 모든 공급 정점 에 대해 가 성립하며 모든 수요 정점 에 대해 가 성립함을 알 수 있다. 공급 정점에는 에서 들어오는 유량(용량)이 추가되고 수요 정점에는 로 나가는 유량(용량)이 추가되기 때문이다. 공급 정점에서 나가는 간선과 수요 정점으로 들어오는 간선은 추가되지 않으므로 와 가 성립한다.
따라서 위의 내용을 바탕으로 식을 정리할 수 있다.
따라서 공급 정점 집합 와 수요 정점 집합 에 속하는 모든 정점에 대해 수요 조건이 성립함을 알 수 있다.
이제 남은 정점들은 공급 정점 집합과 수요 정점 접합 모두에 포함되지 않은 정점들이다. 즉, 인 정점들이다. 이러한 정점들은 슈퍼 소스 노드 또는 슈퍼 싱크 노드와 연결되지 않으므로 추가되는 간선이 없어 이다. 이러한 정점들 또한 flow conservation이 성립하므로
가 성립한다.
따라서 알고리즘에서 유도된 순환 은 실현 가능한 순환임을 알 수 있다.
이때까지 우리는 알고리즘이 ‘예’라고 출력한다면 실현 가능한 순환이 존재한다는 것을 증명했다. 이제 알고리즘이 ‘아니로’라고 출력한다면 실현 가능한 순환이 존재하지 않다는 것을 증명해야 한다. 하지만 일반적으로 존재하지 않음을 증명하는 것은 어렵기 때문에 우리는 이것의 대우 명제, 실현 가능한 순환이 존재하면 알고리즘은 ‘예’를 출력한다를 증명하고자 한다.
실현 가능한 순환 이 존재한다고 가정하자. 알고리즘은 다음과 같은 방식으로 실현 가능한 Flow Network 로 구성하고자 한다.
- 기존 그래프의 모든 간선 에 대해 로 설정한다.
- 모든 공급 정점 에 대해 인 간선을 추가한다.
- 모든 수요 정점 에 대해 인 간선을 추가한다. 위의 방식으로 설계한 Flow network 는 유효한 flow라는 것을 알 수 있다.
- Capacity condition: 기존 간선들의 경우, 같은 용량과 유량을 가지므로 capacity condition을 만족한다. 또한, 새롭게 추가되는 간선의 경우 유량과 용량 모두 연결된 정점의 수요값과 같은 크기로 설정하였기 때문에 capacity condition을 만족한다.
- Flow Conservation:
- : 기존 순환에서 (순유출)이다. 에서의 순유입에 대해
이므로 flow conservation을 만족한다.
- **$u \in T$:** 기존 순환에서 $f_1^{in}(u) - f_1^{out}(u) = d_u$ (순유입)이다. $f_0$에서의 순유입에 대해 $f_1^{in}(u) - f_1^{out}(u) - f_0(u, t) = d_u - d_u = 0$ 이므로 flow conservation을 만족한다.
- $v \in V \setminus \{S, T\}$: 기존 순환에서 $f_1^{in}(v) - f_1^{out}(v) = 0$이다. 새롭게 추가되는 간선이 없으므로 $f_0$에서 $f_0^{in}(v) - f_0^{out}(v) = f_1^{in}(v) - f_1^{out}(v) = 0$이므로 flow conservation을 만족한다.
위의 두 조건을 모두 만족하기 때문에 알고리즘이 생성한 Flow Network는 유효한 flow라는 것을 알 수 있다.
따라서 구성한 는 유효한 유량이다. 이때 에서 나가는 유량의 합은 이고, 로 들어가는 유량의 합은 이다. 컷의 용량이 인 상태에서 크기가 인 유량이 존재하므로, 이는 최대 유량이다. 즉, 가 성립하며, 알고리즘은 포화 여부를 확인하고 ‘예’를 출력하게 된다.
4.5.2. 알고리즘 실행 시간 분석
우리가 처음 본 문제를 알고 있는 문제로 환원하는 알고리즘의 경우 시간 복잡도 계산 시 입력 항목을 명확하게 설정해야 한다.
순환 문제 입력으로 개의 간선과 개의 정점이 들어온다고 설정하자.
그러면 알고리즘이 구성한 Flow Network는 최대 개의 간선을 가지고 개의 정점을 가진다는 것을 알 수 있다. 이를 각각 이라고 설정하자.
4.5.2.1. Theorem 1
순환 알고리즘의 실행 시간은 이다.
4.5.2.1.1. 증명
우선 Flow Network를 구성하는데 필요한 시간을 계산해보자. Flow Network 구성 시 슈퍼 소스 노드, 슈퍼 싱크 노드를 추가( 소요)하고 각 정점들을 슈퍼 소스 노드, 슈퍼 싱크 노드와 연결하는 간선들을 생성(최대 소요)할 것이다. 따라서 Flow Network를 구성하는 과정에서 걸리는 시간은 최대 이다.
이제 생성된 Flow Network에서 최대 유량을 찾는 데 걸리는 시간을 계산해보자. 우리가 이전에 보았던 Edmonds-Karp 알고리즘을 이용하면 의 시간이 소요된다. 이를 원래의 입력값으로 치환하면 , 이다. 이때, Flow Network는 모든 정점은 적어도 하나의 간선과 연결되어 있다고 가정()하므로 이다. 따라서 의 시간이 소요된다.
최대 유량을 구한 후, 추가된 간선들의 포화 여부를 확인하고 원래 그래프의 유량을 출력하는 데에는 정점과 간선을 한 번씩 순회하면 되므로 이 소요된다.
전체 알고리즘의 시간 복잡도는 이다. 이때 은 에 지배되므로(Dominated), 알고리즘의 최종 시간 복잡도는 이다.
시간 복잡도 분석을 위한 가정과 예외 처리
일반적으로 최대 유량 알고리즘의 시간 복잡도 분석( 등)은 **‘고립된 정점이 없다()‘**는 가정을 전제로 한다. 그러나 순환 문제에서 모든 정점의 수요가 0인 경우(), 변환된 네트워크의 슈퍼 소스 와 슈퍼 싱크 는 어떤 정점과도 연결되지 않아 고립된다. 이를 해결하기 위해 알고리즘의 **전처리 단계(Pre-processing)**에서 모든 수요가 0인지 확인한다. 만약 그렇다면 모든 간선의 유량을 0으로 설정해도 성립하므로 즉시 ‘예’를 출력하고 종료한다. 반면, 0이 아닌 수요가 하나라도 존재하는 경우, 수요의 총합이 0이라는 전제()에 의해 반드시 수요 정점()과 공급 정점()이 쌍으로 존재하게 된다. 따라서 와 는 각각 최소 하나 이상의 간선을 갖게 되어 고립되지 않는다. 결론적으로, 이러한 예외 처리를 통해 실질적으로 알고리즘이 수행되는 그래프는 Flow Network의 연결성 가정()을 항상 만족하게 되며, 앞서 유도한 시간 복잡도 상한이 유효해진다.
4.6. Problem 2
(Circulation with demands of lower bounds) 앞의 순환 문제에서 각 간선의 하한 조건을 추가하자. 그래프 는 각각의 간선 는 간선 용량 와 하한 를 가진다. 이때 모든 간선 에 대해 이 성립한다. 또한 각각의 정점 는 수요 를 가지고 있다. 다음의 조건을 만족하는 순환(circulation) 의 존재 여부를 결정하라.
- 각 정점 에 대해 가 성립한다.
- (추가 조건) 각 간선 에 대해 가 성립한다.
4.7. Algorithm
4.7.1. Reduction to Circulation without Lower Bounds
이번 문제는 간선에 흘려보내야 할 최소 유량 하한() 조건이 추가되었다. 우리는 이를 최소 유량 조건이 없는 순환 문제로 환원하여 해결할 것이다. 핵심 아이디어는 “최소 유량만큼을 미리 흘려보냈다고 가정(Pre-flow)“하고 잔여 용량과 수요량을 갱신하는 것이다.
우선 그림을 통해 직관적으로 확인해보자.
Figure 22: transformation to circulation without lower bounds
그림과 같이 간선에 용량 3, 하한 2가 있다고 가정하자. 하한인 2만큼의 유량을 강제로 먼저 흘려보내면, 그래프의 조건은 다음과 같이 수정된다.
- 용량 감소: 2만큼의 용량을 이미 사용했으므로, 잔여 용량은 이 된다. ()
- (시작점) 수요 갱신: 에서 2만큼 나갔으므로, 의 수요값은 2만큼 증가한다. ()
- 예: 기존에 3을 공급()해야 했다면, 2를 미리 보냈으니 1만 더 공급하면 된다().
- (도착점) 수요 갱신: 로 2만큼 들어왔으므로, 의 수요값은 2만큼 감소한다. ()
- 예: 기존에 3을 공급()해야 했는데 2가 더 들어왔으니, 총 5를 공급해야 한다(). 이 방식으로 모든 간선의 하한을 처리하여 새로운 그래프 를 구성한다. 에서 실현 가능한 순환 를 찾은 뒤, 여기에 미리 제외했던 하한값들을 다시 더해주면(), 원래 문제의 조건을 만족하는 순환 를 얻게 된다. 이를 바탕으로 알고리즘을 작성해보자.
4.7.2. Algorithm of Circulation Problem with lower bounds
다음의 순서에 따라 알고리즘을 설계한다.
- 양의 최소 유량 하한을 가지는 간선()에 대해 다음과 같이 재설정한다.
- 용량 를 만큼 감소시킨다()
- 시작점 에 대해 수요값 를 만큼 증가시킨다.()
- 도착점 에 대해 수요값 를 만큼 감소시킨다.()
- 모든 를 0으로 재설정한다.
- 새롭게 생성된 인스턴스(새로운 Flow Network)에서 실현 가능한 순환을 찾는다.
- 인스턴스에 실현 가능한 순환이 없다면 최종 알고리즘은 ‘아니오’를 출력한다.
- 인스턴스가 실현 가능한 순환이 있다면 최종 알고리즘은 ‘예’를 출력한다. 또한, 기존 Flow Network의 하한값을 간선에 더하여() 실현 가능한 순환 또한 출력한다.
4.8. 알고리즘 분석
4.8.1. 알고리즘 정확도 분석
4.8.1.1. Theorem 1
구현한 알고리즘은 정확한 값을 출력한다.
4.8.1.1.1. 증명
기존 그래프 의 간선 에 대해 용량 와 최소 유량 하한 이면, 변환된 그래프 의 용량은 이다(최소 유량 하한은 0). 두 그래프의 유량에 대해 가 성립한다. 다음 두 조건을 모두 만족할 때 하한이 있는 순환 문제와 하한이 없는 순환 문제의 논리적 동치성이 성립한다.
- 에 실행 가능한 순환 이 존재하면 에도 존재한다.
에서의 유량을 로 정의하자.
- Capacity Condition: 이므로, 양변에 을 더하면 , 즉, 가 성립한다.
- 수요 조건 정점 에서 의 수요 조건식에 대해
\begin{align} \sum_{\textit{e into v}}(f(e) - l_e) - \sum_{\textit{e out of v}}(f(e) - l_e) &= \sum_{\textit{e into v}}f(e) - \sum_{\textit{e out of v}}f(e) - \sum l_{in} + \sum l_{out} \&= d_v’ \end{align}
수요량 $d_v' = d_v - \sum l_{in} + \sum l_{out}$이 성립하므로 이항하여 정리하면,\sum_{\textit{e into v}}f(e)
### 1.9.2. 알고리즘 실행 시간 분석 #### 1.9.2.1. Theorem ##### 1.9.2.1.1. 증명 생략 --- > 이 포스트는 연세대학교 컴퓨터과학과 22학번 박철우 학우의 기여로 작성되었다.